یکی از روش های بهبود پرفورمنس در دیتابیس اوراکل استفاده از قابلیت REBUILD کردن ایندکس ها است. REBUILD کردن ایندکس هایی که با روشی مناسب انتخاب می شوند می تواند پرفورمنس دیتابیس را به طور قابل ملاحظه ای بهبود دهد. البته عملیات آنالیز و REBUILD ایندکس زمانبر بوده و سربار ایجاد می کند. در این متن REBUILD ایندکس ها و روش استفاده مناسب از آن توضیح داده می شود.
عملیات I/O به صورت MULTI BLOCK
پارامتر DB_FILE_MULTIBLOCK_READ_COUNT تعداد بلاک هایی که می توانند در هر مرحله از FULL TABLE SCAN با عملیات I/O از دیسک به حافظه منتقل شوند را مشخص می کند البته حداکثر تعداد MULTI BLOCK در زمان اجرا وابسته به پشتیبانی سیستم است. در این متن ویژگی ها و نحوه برخورد اوراکل با این پارامتر را توضیح می دهیم و عملیات خواندن همزمان بلاک ها با یک مثال اجرایی نمایش داده می شود.
انواع SCANهای OPTIMIZER
در دیتابیس اوراکل، OPTIMIZER برای هر دستور SQL مسیرهای دسترسی مختلف به جدول ها را تعیین کرده و با یکدیگر مقایسه می کند تا بهینه ترین مسیر برای EXECUTION PLAN را انتخاب کند. این مقایسه بر اساس آمارهای جمع آوری شده از ایندکس ها و جدول های دیتابیس انجام می شود.
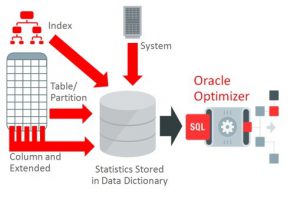
برای هر EXECUTION PLAN مسیر دسترسی نهایی به داده ها با استفاده از عمل SCAN مشخص می شود. در این متن انواع مختلف SCANهای OPTIMIZER توضیح داده می شوند.
شناسایی ایندکس های بی استفاده
ایندکس های بی استفاده سبب ایجاد سربار در عملیات DML می شوند و فضای دیتابیس را هدر می دهند. همانطور که در مطلب روشی برای شناسایی ایندکس های تکراری اشاره شد می توان تعداد موارد بکارگیری ایندکس ها توسط OPTIMIZER در بازه های زمانی گذشته را استخراج کرد و ایندکس های بی استفاده را حذف نمود. در این متن سه روش مختلف برای شناسایی ایندکس های بی استفاده را توضیح می دهیم.
روشی برای شناسایی ایندکس های تکراری
همانطور که در مطلب ایندکس های ترکیبی اشاره شد می توان در کنار ایندکس های عادی، ایندکس های ترکیبی که ترتیب ستون های آنها از اهمیت زیادی برخوردار است ایجاد کرد تا QUERYهای مختلف بتوانند با سرعت بالاتر اجرا شوند.
از طرفی دیگر استفاده از ایندکس های زیاد سبب ایجاد سربار در عملیات DML می شود و فضای دیتابیس را هدر می رود. در این متن یک QUERY برای یافتن ایندکس هایی که ستون های تکراری دارند معرفی می شود.
ایندکس های ترکیبی
ایندکس ترکیبی یا COMPOSITE INDEX برای دو یا چند ستون از جدول تعریف می شود ولی به هر ترتیبی که ستون ها در عبارت ساخت ایندکس قرار گیرند فقط یکسری از QUERYها می توانند از آن ایندکس استفاده کنند. در این متن روش استفاده مناسب از ایندکس های ترکیبی و نحوه عملکرد آنها را توضیح می دهیم.
ایندکس های B-TREE عادی و UNIQUE
ایندکس B-TREE پرکاربردترین ایندکس در دیتابیس اوراکل است که در حالت پیش فرض به صورت غیر UNIQUE ساخته می شود. ایندکس های B-TREE را می توان به صورت UNIQUE نیز تعریف نمود که هیچ تفاوتی از لحاظ PERFORMANCE و ساختار داده ها با ایندکس عادی ندارند. در این متن ساختمان داده و روش عملکرد ایندکس های عادی B-TREEE و UNIQUE را توضیح می دهیم.
ایندکس های FUNCTION BASED
در دیتابیس اوراکل انواع مختلفی از ایندکسها وجود دارند که به منظور بهبود کارایی دیتابیس استفاده می شوند ولی هر کدام از آنها دارای کاربرد و ساختار متفاوت است.
ایندکس ها عناصر اختیاری برای جداول و کلاسترها هستند که می توانند با فراهم نمودن مسیرهای جدید دسترسی به داده ها سبب افزایش سرعت اجرای دستوات SQL شوند. در این متن ایندکس های از نوع FUNCTION BASED و روش استفاده مناسب از آنها را توضیح می دهیم.
اوراکل ZDLRA
ZERO DATA LOSS RECOVERY APPLIANCE یا ZDLRA یک راه حل جامع برای بکاپ و ریکاوری دیتابیس است که توسط شرکت اوراکل ارائه شده است. این راه حل، دیتابیس های اوراکل نسخه 10.2 به بالا که روی هر نوع پلتفرم و سیستم عامل خاص قرار گرفته اند را پشتیبانی می کند. اوراکل ZDLRA از سخت افزار و نرم افزار ویژه تشکیل شده است تا بکاپ و ریکاوری دیتابیس های اوراکل بدون DATA LOSS و با PERFORMANCE بهینه انجام گردد.
فشرده سازی جداول در اوراکل(TABLE COMPRESSION)
در دیتابیس های اوراکل نگارش 9i و بالاتر می توان جدول ها یا پارتیشن ها را فشرده نمود. فشرده بودن یا نبودن جدول ها به طور کامل از دید برنامه نویسان دیتابیس و APPLICATION مخفی است. در ادامه انواع روش های فشرده سازی جدول و ویژگی های آنها را معرفی می کنیم.
در نگارش 9 و 10 اوراکل، فشرده سازی به روش BASIC انجام می گیرد. روش BASIC برای جدول هایی که داده های آنها STATIC هستند مناسب است و در صورت انجام سایر عملیات DML داده های جدول از حالت فشرده خارج خواهد شد.
در نگارش 11 و بالاتر ، روش های دیگر فشرده سازی جدول ارائه شده است که با بکارگیری الگوریتم های خاص امکان استفاده از فشرده سازی برای جدول هایی که عملیات DML روی آنها انجام می شود را فراهم می کند. بنابراین این روش های فشرده سازی مناسب سیستم های OLTP هستند.