در دیتابیس اوراکل، OPTIMIZER برای هر دستور SQL مسیرهای دسترسی مختلف به جدول ها را تعیین کرده و با یکدیگر مقایسه می کند تا بهینه ترین مسیر برای EXECUTION PLAN را انتخاب کند. این مقایسه بر اساس آمارهای جمع آوری شده از ایندکس ها و جدول های دیتابیس انجام می شود.
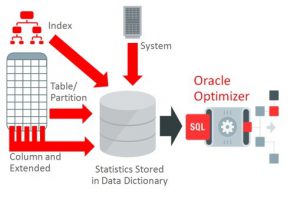
برای هر EXECUTION PLAN مسیر دسترسی نهایی به داده ها با استفاده از عمل SCAN مشخص می شود. در این متن انواع مختلف SCANهای OPTIMIZER توضیح داده می شوند.
زمانی که روی ستون های جداول دیتابیس ایندکس تعریف می شود OPTIMIZER می تواند برای انتخاب مسیر نهایی از SCAN ایندکس ها استفاده کند البته به شرطی که تشخیص دهد هزینه انتخاب آن مسیر بهتر از مسیر بدون ایندکس است. بنابراین OPTIMIZER برای هر دستور SQL میسرهای مختلف دسترسی به داده های دیتابیس را مشخص می کند تا از بین آنها مسیر مناسب انتخاب گردد.
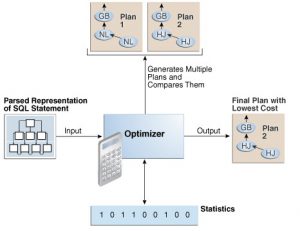
اگر در موارد زیر ایندکس ساخته شود OPTIMIZER در بیشتر موارد از SCANهای ایندکس استفاده می کند:
-ساخت ایندکس برای ستون هایی که معمولا سبب انتخاب کمتر از 5 درصد داده های جدول می شوند (ساخت ایندکس درختی در سیستم های OLTP).
-ساخت ایندکس برای ستون هایی که به تعداد دفعات زیاد در QUERYها و معمولا در قسمت عبارت WHERE استفاده می شوند.
نکته: صرف نظر از اینکه OPTIMIZER از SCAN ایندکس استفاده می کند یا نه برای ستون هایی که FOREIGN KEY هستند باید ایندکس ساخته شود در غیر این صورت هر زمان که عملیات DML روی ستون REFRENCE در جدول PARENT انجام می شود جدول CHILD به طور کامل LOCK می شود و می تواند مشکل پرفومنسی ایجاد کند.
نکته: SORT در ایندکس های درختی ابتدا بر اساس VALUE و سپس بر اساس ROWID انجام می شود.
نکته: اگر در دستور SQL فقط به مقدار همان ستون ایندکس شده نیاز باشد OPTIMIZER مقدار نهایی را از ایندکس برمی گرداند وگرنه ROWID متناظر برای جدول برگردانده می شود.
INDEX UNIQUE SCAN
زمانی که از این نوع SCAN استفاده می شود فقط یک مقدار نهایی برگردانده می شود. بنابراین OPOTIMIZER به محض یافتن اولین نتیجه، متوجه می شود که عملیات جستوجو تمام شده است و نتیجه را برمی گرداند.
نکته: با توجه به ساختار درختی ایندکس، هزینه برای هر جستجو برابر با جستجوهای دیگر خواهد بود.
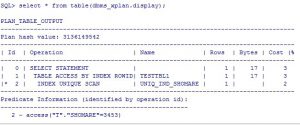
نکته: هر زمان که در عبارت WHERE برای یک ستون که ایندکس UNIQUE دارد از عبارت ‘=’ استفاده گردد از INDEX UNIQUE SCAN استفاده می شود:
SQL> explain plan for select * from milad.testtbl1 t where t.shomare=3453;
Explained
FAST FULL INDEX SCAN
این نوع SCAN همانند روش FULL TABLE SCAN به صورت MULTI BLOCK READ انجام می شود بنابراین داده ها به صورت عادی مرتب نیستند و نیاز به SORT کردن داده ها دارد. از طرفی دیگر در این نوع SCAN تمام داده ها از ایندکس برگردانده می شوند و نیاز به خواندن اطلاعات جدول نیست بنابراین سرعت بالاتر خواهد بود.
نکته: اگر ستونی که ایندکس از نوع UNIQUE دارد CONSTRANT از نوع NOT NULL یا PRIMARY KEY داشته باشد در QUERYهایی که COUNT آن ستون گرفته می شود OPTIMIZER معمولا از روش FAST FULL INDEX SCAN استفاده می کند:
SQL> explain plan for select shomare from milad.testtbl1;
Explained
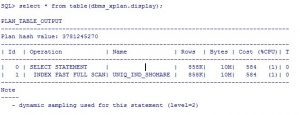
نکته: اگر در یک QUERY از عبارت ORDER BY استفاده شود OPTIMIZER از روش FAST FULL INDEX SCAN استفاده نمی کند زیرا می بایست عمل SORT انجام گردد و هزینه نهایی افزایش می یابد.
نکته: اگر از موازی سازی استفاده شود SCAN FAST FULL INEX نیز قابل اجرا خواهد بود.
نکته: تمام ستون های ایندکس ترکیبی باید در QUERY استفاده شده باشند تا OPTIMIZER برای آن QUERY از عمل FAST FULL INDEX SCAN استفاده کند:
Create index comp_ind on testtbl2(col1,col2,col3);
SELECT col1,col2,col3 from testtbl2;
نکته: تعداد عملیات I/O زمانی که multi block read داریم وابسته به پارامتر DB_FILE_MULTIBLOCK_READ_COUNT خواهد بود.
FULL INDEX SCAN
در این SCAN برخلاف FAST FULL INDEX SCAN خواندن داده ها به صورت ترتیبی و با سرعت کمتر خواهد بود. البته این نوع SCAN نیاز به عمل SORT ندارد زیرا داده های ایندکس که به صورت ترتیبی خوانده می شوند SORT شده هستند.
نکته: اگر در عبارت WHERE هیچ PREDICATE تعیین نشود OPTIMIZER می تواند از این نوع SCAN استفاده کند.
نکته: وقتی OPTIMIZER به این نتیجه برسد که نتیجه نهایی با FULL INDEX SCAN قابل دستیابی است ولی FULL TABLE SCAN به همراه عملSORT هزینه بالاتری دارد از FULL INDEX SCAN استفاده می شود.
نکته: اگر در دستور SQL عمل GROUP BY یا ORDER BY روی ستون ایندکس شده انجام شود معمولا از INDEX FULL SCAN استفاده شود:
SQL> explain plan for select shomare from milad.testtbl1 order by shomare;
Explained
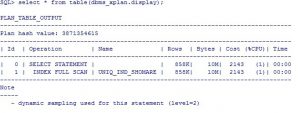
اگر QUERY بالا با FAST FULL INDEX SCAN اجرا شود COST به دلیل نیاز به عمل SORT بالا خواهد بود:
SQL> explain plan for select /*+ index_ffs(testtbl1, uniq_ind_shomare) */ shomare from milad.testtbl1 order by shomare;
Explained
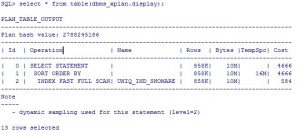
INDEX RANGE SCAN
زمانی که نتیجه نهایی بیشتر از یک سطر از جدول باشد و به محدوده ای از داده های ایندکس شده نیاز است از این نوع SCAN استفاده می شود.
SQL> explain plan for select * from milad .testtbl1 where shomare between 100 and 500;
Explained
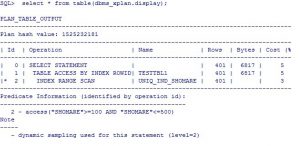
نکته: اگر در دستور SQL عمل GROUP BY یا ORDER BY روی ستون ایندکس شده انجام شود ممکن است از RANGE SCAN استفاده شود.
نکته: INDEX RANGE SCAN می تواند از نوع نزولی یا DESCENDING نیز باشد.
INDEX SKIP SCAN
این نوع از SCAN مربوط به ایندکس های با بیش از یک ستون است که در مطلب ایندکس های ترکیبی توضیح داده شده است.
FULL TBLE SCAN
در SCAN FULL TABLE از ایندکس ها استفاده نمی شود بلکه تمام جدول از دیسک به حافظه منتقل می گردد(البته به روش MULTI BLOCK) و سپس عملیات مقایسه برای دسترسی به داده های نهایی انجام می گردد حتی اگر فقط به چند سطر از جدول نیاز باشد.
نکته: این نوع SCAN همانند FAST FULL INDEX SCAN نیاز به SORT دارد.
نکته: در موارد زیر از FULL TABLE SCAN استفاده می شود:
-زمانی که ایندکس مناسب تعریف نشده است.
-اندازه جدول کوچک است.
-PREDICATEهای مناسب در عبارت WHERE تعیین نشده اند یا از لحاظ SELECTIVITY استفاده از ایندکس به صرفه نیست.
– اگر درجه موازی سازی بالا باشد از عمل FULL TABLE SCAN استفاده می شود.
-اگر آمارهای جداول و ایندکس ها قدیمی و STALE باشند.
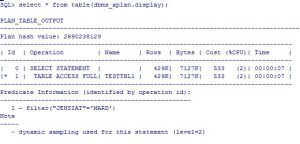
مثال:
SQL> explain plan for select * from milad.testtbl1 where jensiat=’MARD’;
Explained
عالی بود
عالی و کاربردی