در دیتابیس اوراکل انواع مختلفی از ایندکسها وجود دارند که از آنها به منظور بهبود کارایی دیتابیس استفاده می شود ولی هر کدام دارای کاربرد و ساختار متفاوت هستند. در این متن ایندکس های از نوع BITMAP که فقط در نسخه های ENTERPRISE اوراکل قابل تعریف و استفاده هستند را توضیح می دهیم.
سه نمونه از محدودیتهای فیچر auto indexing در اوراکل 19c
auto indexing یکی از قابلیتهای مهم اوراکل نسخه 19c است که در مورد این قابلیت، پیشتر مطلبی را نوشتیم(ویژگی Automatic Indexing در اوراکل 19c). در این متن به برخی از محدودیتهای این قابلیت در نسخه 19c خواهیم پرداخت البته بسیار روشن است که در نسخه های آتی اوراکل ممکن است این محدودیتها برطرف شود بنابرین باید توجه داشته باشید که سناریوهای موجود در متنی که در حال مطالعه آن هستید، در نسخه 19c(بطور دقیق تر 19cR8) تست شده است.
روشی برای تسریع در “حذف حجم بالای از اطلاعات یک جدول”
شرایط جدول mtbl را در نظر بگیرید:
SQL> select count(*) from mtbl;
16777216
SQL> select to_char(creation_time,’YYYY’,’nls_calendar=persian’),count(*) from mtbl group by to_char(creation_time,’YYYY’,’nls_calendar=persian’) order by 1 desc;
TO_CHAR(CREATION_TIME,’YYYY’,’ COUNT(*)
—————————— ———-
1399 262144
1397 3932160
1396 4194304
1395 4194304
1394 4194304
Executed in 4.563 seconds
حجم جدول mtbl:
SQL> select bytes/1024/1024 SIZE_MB from user_segments p where p.segment_name=’MTBL’;
SIZE_MB
———-
4286
قصد داریم رکوردهایی از این جدول که creation_time آنها مربوط به سال 1399 بوده را در جدول حفظ کرده و مابقی اطلاعات را حذف کنیم.
سناریوی عملی برای مشاهده نقش CLUSTERING_FACTOR خوب و بد
در مبحث “آشنایی با Clustering Factor در اوراکل” مطالبی را در مورد CLUSTERING_FACTOR ارائه دادیم در این مطلب قصد داریم با چند مثال عملی را در این زمینه ارائه کرده و در پایان، هزینه استفاده از ایندکس را برای هر دو حالت با هم مقایسه خواهیم کرد.
مثال 1(CLUSTERING_FACTOR بد): قصد داریم با اجرای پرس و جوی زیر، اطلاعاتی از جدول badcftable را در خروجی نمایش دهیم:
SQL> Select * from badcftable where code=2;
آشنایی با Clustering Factor در اوراکل
قصد داریم از طریق یکی از ایندکسهای جدول، به تک تک رکوردهای آن جدول دسترسی پیدا کنیم به این صورت که ابتدا آدرس فیزیکی یا همان rowid رکورد را از طریق ایندکس پیدا کرده و سپس با انتقال Data Block حاوی آن رکورد به حافظه، جدول را scan کنیم.
از آنجایی که اطلاعات در ایندکس به صورت “مرتب” ذخیره می شوند، هر چه ترتیب قرار گرفتن رکوردها در جدول مشابه ترتیب قرارگیری keyها در ایندکس باشد، نیاز به I/O کمتری خواهیم داشت و SCAN جدول از طریق ایندکس می تواند با سرعت بیشتری انجام شود.
به عبارتی دیگر اگر در یک Leaf Block پنج index entry موجود باشد، در بهترین حالت هر پنج رکورد متناظر با index entryها، در یک Data Block قرار می گیرند و در بدترین حالت، هرکدام از این رکوردها در یک بلاک مجزا در جدول ذخیره شده اند.
انجام query rewrite با استفاده از DBMS_ADVANCED_REWRITE
فرض کنید پرس و جوی زیر یکی از پرس و جوهای پراستفاده برنامه می باشد که به دلیل عدم دسترسی به سورس کد برنامه امکان تغییر متن آن وجود ندارد:
SQL> select /*+INDEX(tbl1,IND_CODE)*/ count(*) from tbl1 where code=2 ;
COUNT(*)
———-
51199980
Elapsed: 00:00:05.23

همانطور که می بینید، این پرس و جو حدودا در زمان 4 ثانیه اجرا شده است با برداشتن HINTای که در این پرس و جو موجود است، آن را مجددا اجرا می کنیم:
SQL> select count(*) from tbl1 where code=2 ;
COUNT(*)
———-
51199980
Elapsed: 00:00:01.60

مشاهده می کنید که زمان اجرای پرس و جو با برداشتن HINT از 5 ثانیه به 1 ثانیه کاهش پیدا کرده است قصد داریم با هر بار اجرای پرس و جوی اول، دیتابیس به صورت خودکار پرس و جوی دوم(که فاقد HINT است) را اجرا کند به عبارتی دیگر، دیتابیس در پس زمینه query rewrite را انجام دهد.
خارج کردن اطلاعات یک دستور از shared pool
ممکن است در شرایطی بخواهید صرفا فرم پارس شده یکی از دستورات را از حافظه خارج کنید، در این صورت می توانید از بسته DBMS_SHARED_POOL.PURGE استفاده کنید.
SQL>select ADDRESS, HASH_VALUE,sql_text from V$SQLAREA where SQL_TEXT like ‘%delete mytbl where %’ and SQL_TEXT not like ‘%v$sql%’;

SQL> exec sys.DBMS_SHARED_POOL.PURGE ‘00000000774B91E0,3503309987′,’C’);
PL/SQL procedure successfully completed
SQL>select ADDRESS, HASH_VALUE,sql_text from V$SQLAREA where SQL_TEXT like ‘%delete mytbl where %’ and SQL_TEXT not like ‘%v$sql%’;
no rows selected
توجه: پارامتر دوم در پروسیجر Purge(کارکتر C)، به نوع object اشاره دارد که علامت اختصاری objectها را در قسمت زیر می بینید:
–P package/procedure/function –JS java source
–Q sequence –JC java class
–R trigger –JR java resource
–T type –JD java shared data
نکته ای در مورد elapsed_time برای parallel queyها
در گزارش AWR و همچنین ویوهایی نظیر V$SQLه، elapsed_timeای که برای parallel queryها نمایش داده می شود، جمع بین زمان سپری شدهquery coordinator و parallel query slaveها می باشد از این جهت، نباید این عدد را با elapsed_time واقعی پرس و جو اشتباه گرفت.
مثال زیر را ببینید:
SQL> select /*+parallel(3)*/ sum(id),sum(code),avg(count) from usef.myview;
SUM(ID) SUM(CODE) AVG(COUNT)
———- ———- ———-
713031680 3548381184 68.1508522
Elapsed: 00:01:18.89
SQL> /
SUM(ID) SUM(CODE) AVG(COUNT)
———- ———- ———-
713031680 3548381184 68.1508522
SQL> /
Elapsed: 00:01:17.08
SQL> /
SUM(ID) SUM(CODE) AVG(COUNT)
———- ———- ———-
713031680 3548381184 68.1508522
Elapsed: 00:01:17.94
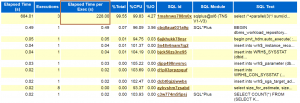
پس از اجرای دستورات فوق، در گزارش AWR خواهیم دید که Elapsed Time برای query اجرا شده برابر با 228 ثانیه می باشد در صورتی که این query در مدت زمان80 ثانیه(حدودا) اجرا شده است:
External Table و In-Memory – اوراکل 18c
تا قبل از اوراکل 18c، امکان استفاده از قابلیت in memory برای جداول از نوع external وجود نداشت:
SQL*Plus: Release 12.2.0.1.0 Production on Mon May 18 12:05:36 2020
SQL> alter table mytbl inmemory;
ORA-30657: operation not supported on external organized table
این قابلیت در اوراکل 18c برای محیط exadata ارائه شد.
Connected to Oracle Database 18c Enterprise Edition Release 18.0.0.0.0
SQL> alter table mytbl inmemory;
ORA-12755: Feature In-Memory External Tables is disabled due to unsupported capability.
SQL> alter system set “_exadata_feature_on”=true scope=spfile;
System altered.
SQL> startup force;
SQL> alter table mytbl inmemory;
Table altered
SQL> SELECT table_name, inmemory, inmemory_compression FROM user_external_tables;
TABLE_NAME INMEMORY INMEMORY_COMPRESSION
———– ——— ———————-
MYTBL ENABLED FOR QUERY LOW
ADO و مدیریت in-memory
همانطور که می دانید، objectهای که خصیصه inmemory برای انها تنظیم شده متناسب با اولویتی که دارند، در in-memory قرار خواهند گرفت برای مثال، اگر خصیصه inmemory برای جدولی با اولویت critical تعریف شده باشد، این جدول صرف نظر از تعداد دفعات رجوع، در زمان استارت دیتابیس در in memory قرار خواهد گرفت.
در این متن به این سوال پاسخ خواهیم داد که چگونه می توان از قرار گرفتن جدول و یا به صورت کلی objectای که مدت زمان زیادی از آخرین زمان دستیابی و یا اصلاح آن گذشته، به in-memory جلوگیری کرد(آن هم به صورت خودکار)؟
این کار در نسخه 12cR2 با کمک ویژگی (Automatic Data Optimization(ADO قابل انجام است همانطور که می دانید ADO که در نسخه 12cR1 ارائه شد، امکان جابجایی و فشرده سازی objectها را متناسب با آمارهای heat map فراهم می سازد. به عنوان بهبودی جدید در نسخه 12cR2، امکان ایجاد ADO policy برای خصیصه inmemory جداول هم امکان پذیر می باشد(در سطح segment).