ایندکس B-TREE پرکاربردترین ایندکس در دیتابیس اوراکل است که در حالت پیش فرض به صورت غیر UNIQUE ساخته می شود. ایندکس های B-TREE را می توان به صورت UNIQUE نیز تعریف نمود که هیچ تفاوتی از لحاظ PERFORMANCE و ساختار داده ها با ایندکس عادی ندارند. در این متن ساختمان داده و روش عملکرد ایندکس های عادی B-TREEE و UNIQUE را توضیح می دهیم.
ایندکس B-TREE
در تصویر زیر ساختمان داده ایندکس B-TREE را می بینید. ایندکس نمایش داده شده در این تصویر مربوط به ستونی از جدول است که در آن شماره دپارتمان ها بین عدد 0 تا 250 ذخیره شده اند.
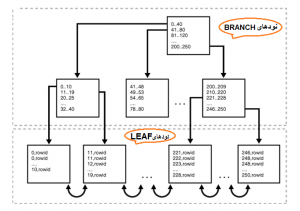
در ساختمان داده ایندکس B-TREE مقدارها در محدوده های مرتب شده قرار می گیرند. این ایندکس ها از دو مدل نود ساخته می شوند:
1.نودهای BRANCH:
این نودها برای جستجو و دستیابی به مقدارهای ستون مورد نظر پیمایش می شوند. نودهای BRANCH شامل داده هایی هستند که به آنها KEY می گویند و با استفاده از آنها می توان به آدرس و مقدارهای ستون مورد نظر رسید. هر نود BRACH دارای اشاره گر به اولین بلاک از BRANCH های بعدی است که براساس KEY از هم جدا شده اند.
2.نودهای های LEAF :
در سطح آخر از ساختمان داده B-TREE، نودهای BRANCH به نودهای LEAF اشاره می کنند. در نود LEAF مقدارهای ستون به همراه ROWID ذخیره می شوند. از آنجایی که هر B-TREE به صورت بالانس شده است تمام نودهایLEAF در عمق یکسان قرار می گیرند و دارای ارتفاع یکسان هستند. بنابراین بازیابی یک رکورد از هر قسمت از ایندکس، به طور تقریبی از لحاظ زمانی یکسان است.
بنابراین در نود های LEAF، ترکیب های (KEY,ROWID) در محدوده مورد نظر ذخیره می شوند. KEY همان مقدار ایندکس شده و ROWID آدرس فیزیکی سطری از جدول است که شامل آن مقدار است. این ترکیب ها مرتب شده هستند (ابتدا بر اساس KEY و سپس بر اساس ROWID مرتب و ذخیره می شوند).
فرض کنید برای جدول EMPLOYEES ایندکس تصویر بالا ساخته می شود:
Create index emp_dep_ind on EMPLOYEES(DEPARTMENT_ID);
در ادامه QUERY زیر اجرا می شود:
select * from EMPLOYEES where DEPARTMENT_ID=221;
در این ایندکس عمق ساختمان داده برابر با 3 است بنابراین OPTIMIZER با استفاده از 3 واحد زمانی به مقدار 221 در نود LEAF می رسد و ROWID سطرهای مورد نظر را استخراج می کند.
نکته: می توان از هر ترکیب (KEY,ROWID) در نودهای LEAF به ترکیب قبلی و بعدی دسترسی داشت و نیاز نیست ازابتدا یک پیمایش مجرا روی ساختمان داده انجام گردد. همچنین با استفاده از اشاره گرها هر نود LEAF به نودهای LEAF همجوار متصل است.
نکته: اگر ستونی با نوع داده کاراکتری تعریف شود ساختار ایندکس B-TREE و تقسیم بندی KEYها برای آن ستون بر اساس مقدار باینری عبارت کاراکتری خواهد بود.
نکته: تقسیم بندی محدوده KEYها در نود های BRANCH بر اساس طول آنها و سایز بلاک در دیتابیس تعیین می شود. نودی که دارای n عدد KEY است n+1 نود CHILD خواهد داشت.
نکته: مقدارهای NULL در ساختمان داده B-TREE ذخیره نمی شوند. بنابراین اگر برای ستون col ایندکس B-TREE تعریف شده باشد QUERY زیر نمی تواند از این ایندکس استفاده کند:
select * from testtbl where col is null;
ایندکس B-TREE از نوع UNIQUE
ایندکس از نوع UNIQUE از لحاظ ساختمان داده هیچ تفاوتی با ایندکس B-TREE عادی ندارد و دستورات SELECT در دیتابیس همانند ایندکس عادی از آنها استفاده می کنند.
تنها تفاوت ایندکس های عادی با ایندکس های UNIQUE برقرار شدن محدودیت برای داده ها در عملیات DML می باشد. از آنجایی که در عملیات DML ایندکس نیز بروزرسانی می شود برای ستون هایی که ایندکس UNIQUE دارند نمی توان داده تکراری درج یا بروزرسانی نمود حتی اگر آن ستون CONSTRAINT از نوع UNIQUE یا PRIMARY KEY نداشته باشد.
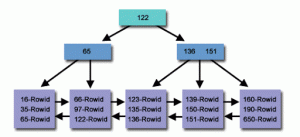
نکته: به دلیل UNIQUE بودن داده ها، فقط یک ترکیب (KEY,ROWID) متمایز در نودهای LEAF خواهیم داشت.
مثال:
SQL> create table milad.persons(id number,nam varchar2(40));
Table created
SQL>
Begin
For i in 500..550
Loop
Insert into milad.persons(id)
values(i*5);
Commit;
End loop;
End;
/
SQL> create unique index milad.id_ind on milad.persons(id);
Index created
SQL> update milad.persons set id=2500 where id=2550;
ORA-00001: unique constraint (MILAD.ID_IND) violated
SQL>
SQL> select CONSTRAINT_NAME from dba_constraints d where d.table_name=’PERSONS’ and d.owner=’MILAD’;
CONSTRAINT_NAME
——————————
SQL>
نکته: توجه شود که نمی توان به ستونی از جدول که دارای ایندکس UNIQUE است ولی CONSTRAINT از نوع UNIQUE یا PRIMARY KEY ندارد REFRENCE داد.
نکته: زمانی که به یک ستون از جدول CONSTRAINT از نوع UNIQUE یا PRIMARY KEY اختصاص می یابد دیتابیس به صورت اتوماتیک یک ایندکس UNIQUE با نام پیش فرض اوراکل برای آن ستون ایجاد می کند (اگر آن ستون ایندکس نداشته باشد).
نکته: می توان برای یک ستون با CONSTRAINT از نوع UNIQUE یک ایندکس عادی استفاده نمود و بلعکس.