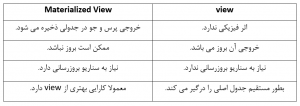
همانطور که می دانید ویو(view) ذخیره پرس و جو در بانک اطلاعاتی به یک اسم خاص می باشد که عمده کاربرد آن در امنیت و استقلال منظقی داده ها می باشد ویوها هیچ فضایی را برای ذخیره داده مصرف نمی کنند و با هر بار اجرا، پرس وجو را هم اجرا می کنند. همانند ویو، شی دیگری نیز وجود دارد که شامل یک پروس و جو می باشد که برخلاف ویو، خروجی پرس و جو را هم در جایی ذخیره می کند و در مواقع ضروری می توان آن را بروز کرد این شی Materialized View نام دارد.
به صورت خلاصه، در جدول زیر تفاوتMaterialized View و view آورده شده است:
مثال زیر به صورت عینی تری تفاوت این دو را نشان می دهد:
ابتدا جدولی را ایجاد می کنیم و سپس بر روی آن، view و materialzed viewای را هم ایجاد می کنیم:
create table tbl1 as select name,file# from v$datafile;
create view v_tbl1 as select * from tbl1;
create materialized view mv_tbl1 as select * from tbl1;
در این صورت، خروجی هر سه دستور زیر، به صورت یکسان خواهد بود:
select * from tbl1;
select * from v_tbl1;
select * from mv_tbl1;
NAME FILE#
——————————————— ———-
+DATA01/usef/datafile/system.256.928615183 1
+DATA01/usef/datafile/sysaux.257.928615183 2
+DATA01/usef/datafile/undotbs1.258.928615183 3
+DATA01/usef/datafile/users.259.928615185 4
+DATA01/usef/datafile/undotbs2.264.928615271 5
سوال: تفاوت این سه شی در چیست؟ تفاوت این سه شی با دستور بعدی مشخص می شود و با استفاده از rowid، تفاوت انها مشهود خواهد بود چون rowid آدرس فیزیکی رکورد را نشان خواهد داد:
select rowid from tbl1 where file#=1; ==> AAAR74AABAAAUeZAAA
select rowid from v_tbl1 where file#=1; ==> AAAR74AABAAAUeZAAA
select rowid from mv_tbl1 where file#=1; ==> AAAR76AABAAAUf5AAA
همانطور که می بینید، view و جدول برای رکورد مورد نظر، rowid یکسانی دارند اما materialzed view آن rowid متفاوتی را بر می گرداند که به منزله تفاوت فیزیکی این اشیا می باشد.
توجه: برای راحتی در نوشتار، در ادامه از mv به جای materialzed view استفاده شده است.
mvها از چند جنبه قابل بررسی می باشند که جدول زیر نمای کلی از آن را ارائه می دهد:

در ادامه در مورد هر یک از این موارد، مطالبی آورده خواهد شد.
Refresh Type
همانطور که مطرح شد، mv برخلاف view،خروجی دستور را در جدولی ذخیره می کند و تنها یک بار و آن هم در زمان ساخت به جدول اصلی رجوع می کند این موضوع سبب می شود تا هرگونه تغییر در جدول مبنا، در جدول mv اعمال نشود و به همین دلیل باید به روشی این اطلاعات تغییر یافته را در mv هم اعمال کرد.
به چهار روش می توان در مورد بروزرسانی mvها اعمال نظر کرد که در ادامه هر کدام از این چهار روش، به صورت مختصر مورد بررسی قرار خواهند گرفت.
1.COMPLETE REFRESH : با این روش در هر بار بروزرسانی، داده ها به صورت کامل از جدول مبنا وارد جدول mv خواهند شد. برای انجام بروزرسانی به این روش، می توان از دستور زیر استفاده کرد:
execute dbms_mview.refresh( list => ‘MV_TBL2’, method => ‘C’ );
روال انجام این نوع از بروزرسانی، به صورت زیر می باشد:
1.ابتدا تمامی رکوردهای جدول mv حذف می شوند(بدون انجام commit یا rollback)
2.سپس داده جدید وارد جدول مربوط به mv می شود.
3.و در نهایت commit یا rollback انجام می شود.
توجه: پیشنهاد می شود مطلب “بروزرسانی کامل MV به صورت non-atomic” را هم مطالعه بفرمایید.
2.FAST REFRESH : این روش از بروزرسانی، با استفاده از آخرین تغییراتی که در materialized view log نسبت به اخرین اطلاعات MV ثبت شده، بروز رسانی را انجام می دهد(materialized view log در ادامه به طور مفصل مورد بررسی قرار خواهد گرفت) یعنی برخلاف روش بروزرسانی کامل، این روش نیازی به بروزرسانی کل جدول در هر بروزرسانی نخواهد داشت.
برای استفاده از این روش، جدول مبنا الزاما باید از materialized view log استفاده کند و در صورت فقدان MLOG(materialized view log) برای جدول مبنا، ایجاد MV با این روش از بروزرسانی با خطا مواجه خواهد شد. خطای مربوطه به صورت زیر می باشد:
ORA-23413: table “USEF”.”TBL1″ does not have a materialized view log
در ادامه مثالی از نحوه ایجاد mv آورده شده است که شیوه بروزرسانی آن، fast می باشد.
ابتدا روی جدول مبنا MLOG را ایجاد می کنیم:
create materialized view log on ag1;
سپس mv مورد نظر را با استفاده از پرس و جو مربوطه ایجاد خواهیم کرد:
CREATE MATERIALIZED VIEW MV2 REFRESH fast ON DEMAND AS select * from ag1;
برای انجام تست بروزرسانی، روی جدول مبنا اطلاعاتی را درج می کنیم:
insert into ag1 values(21,10,4);
commit;
و در نهایت بروزرسانی را انجام می دهیم:
execute dbms_mview.refresh( list => ‘USEF.MV2’, method => ‘F’ );
در ادامه تریس مربوط به این بروزرسانی آورده شده است:
PARSING IN CURSOR #139980308362368 len=181 dep=1 uid=103 oct=7 lid=103 tim=13301422658836 hv=876999841 ad=’2fb7341b8′ sqlid=’gjsvvx0u4bx51′
DELETE FROM “USEF”.”MV2″ SNAP$ WHERE “A” IN (SELECT * FROM (SELECT MLOG$.”A” FROM “USEF”.”MLOG$_AG1″ MLOG$ WHERE “SNAPTIME$$” > :1 AND (“DMLTYPE$$” != ‘I’)) AS OF SNAPSHOT(:B_SCN) );
PARSING IN CURSOR #139980308362368 len=596 dep=1 uid=103 oct=189 lid=103 tim=13301422662008 hv=3335971313 ad=’2fb667dc8′ sqlid=’cvdyza33ddsgj’
/* MV_REFRESH (MRG) */ MERGE INTO “USEF”.”MV2″ “SNA$” USING (SELECT * FROM (SELECT CURRENT$.”A”,CURRENT$.”B”,CURRENT$.”C” FROM (SELECT “AG1″.”A” “A”,”AG1″.”B” “B”,”AG1″.”C” “C” FROM “AG1” “AG1″) CURRENT$, (SELECT DISTINCT MLOG$.”A” FROM “USEF”.”MLOG$_AG1″ MLOG$ WHERE “SNAPTIME$$” > :1 AND (“DMLTYPE$$” != ‘D’)) LOG$ WHERE CURRENT$.”A” = LOG$.”A”) AS OF SNAPSHOT(:B_SCN) )”AV$” ON (“SNA$”.”A” = “AV$”.”A”) WHEN MATCHED THEN UPDATE SET “SNA$”.”A” = “AV$”.”A”,”SNA$”.”B” = “AV$”.”B”,”SNA$”.”C” = “AV$”.”C” WHEN NOT MATCHED THEN INSERT (SNA$.”A”,SNA$.”B”,SNA$.”C”) VALUES (AV$.”A”,AV$.”B”,AV$.”C”);
قابلیتهای mvها
برای بررسی امکان پذیری بروزرسانی به صورت fast refresh می توان از پروسیجر DBMS_MVIEW.EXPLAIN_MVIEW بهره گرفت این پروسیجر تمامی قابلیتهای یک mv را مشخص می کند و به سوالهایی از قبیل سوالهای زیر پاسخ می دهد:
آیا mv قابلیت بروزرسانی fast را دارد؟
آیا mv قابلیت query rewrite را پشتیبانی می کند؟
و….
همچنین به فرض عدم پشتیبانی قابلیتی، به این سوال هم پاسخ می دهد که به چه دلیل، mv مورد نظر، این قابلیت را پشتیبانی نمی کند؟
برای بررسی mvها با استفاده از پروسیجر explain_mview، باید ابتدا جدولی با اسم mv_capabilities_table ساخته شود، اجرای اسکریپت زیر، سبب ایجاد جدولی با ساختار مورد نظر می شود:
@$ORACLE_HOME/rdbms/admin/utlxmv.sql
سپس با داشتن نام mv مورد نظر، می توان بررسی کرد که این mv چه عملیاتی را پشتیبانی می کند. البته ابتدا جدول مربوطه را خالی می کنیم تا فقط اطلاعات مربوط به mv مورد نظر در خروجی دیده شود:
truncate table mv_capabilities_table;
سپس با استفاده از یکی از دو دستور زیر، پروسیجر مربوطه را اجرا می کنیم:
exec DBMS_MVIEW.explain_mview(‘MV1’);
دستور دوم، تنها به جای نام mv، از متن mv استفاده کرده است:
exec dbms_mview.explain_mview(‘CREATE MATERIALIZED VIEW mv1 REFRESH complete ON DEMAND AS select * from ag1’);
در نهایت، دستور زیر نشان می دهد که این MV، چه قابلیتهایی را پشتیبانی می کند:
select capability_name,possible,msgtxt from mv_capabilities_table;
محدودیتها fast refresh
این روش از بروزرسانی، محدودیتهایی را هم در پی دارد که چند نمونه از آن در ادامه آورده شده است:
- در دستور Select نمی توان ستونی با نوع دادهRAW یا LONG RAWرا صدا زد.
- وجود عبارات زیر در دستورselect مجاز نمی باشد:
MODEL – (ANY – ALL – NOT EXISTS) – CONNECT BY – HAVING
- در صورت استفاده از group by، باید لیست ستونهای group by در لیست select هم موجود باشند:
CREATE MATERIALIZED VIEW MV1 REFRESH FAST ON DEMAND AS select count(*) from ag1 group by b;
ORA-12015: cannot create a fast refresh materialized view from a complex query
شکل صحیح آن به صورت زیر می باشد:
CREATE MATERIALIZED VIEW MV1 REFRESH FAST ON DEMAND AS select b,count(*) from ag1 group by b;
- در لیست فیلدهای موجود در دستور select، نمی توان از subquery استفاده کرد:
CREATE MATERIALIZED VIEW MV3 REFRESH fast ON DEMAND AS select b,(select max(b) from ag1) from ag1;
ORA-22818: subquery expressions not allowed here
- در صورت استفاده از ستونی با نوع داده char در MLOG، باید کارکترست در بانک مبدا و مقصد یکسان باشند.
3.FORCE REFRESH : استفاده از این روش سبب می شود تا بروزرسانی در صورت امکان بصورت FAST REFRESH انجام شود و در صورتی که شرایط برای بروزرسانی به صورت FAST فراهم نباشد، بروزرسانی به شیوه COMPLETE انجام خواهد شد. اگر در مورد شیوه بروزرسانی نظری داده نشود، FORCE مقدار پیش فرض خواهد بود.
Build Method
جدول مربوط به mv می تواند به طروق مختلفی ایجاد شود که در ادامه سه روش ممکن در این زمینه را به طور مختصر، تشریح کردیم.
1.BUILD IMMEDIATE: بلافاصله بعد از اجرای دستور ساخت mv، جدول به صورت کامل و همراه با داده ایجاد می شود:
CREATE MATERIALIZED VIEW mv_tbl5 BUILD IMMEDIATE AS select file#,name from tbl1;
SQL> select count(*) from mv_tbl5;
COUNT(*)
———-
7
2.BUILD DEFERRED :جدول مربوط به mv بدون داده ایجاد می شود و با اولین بروزرسانی، داده ها وارد جدول خواهند شد:
CREATE MATERIALIZED VIEW mv_tbl54 BUILD DEFERRED AS select file#,name from tbl1;
SQL> select count(*) from mv_tbl54;
COUNT(*)
———-
0
زمانی که قرار باشد تعدادی MV برای یک بانک اطلاعاتی ساخته شود و در همین حال زمان فعلی برای این کار مناسب نباشد، می توان جدول mv را بدون داده ایجاد کرد و همچنین با تعریف job و انجام بروزرسانی در زمان مناسب، داده ها را وارد جدول کرد.
3.PREBUILT TABLE: در صورتی که بخواهیم از جدول از پیش ساخته شده استفاده شود و ایجاد جدول جدید صورت نپذیرد، از عبارت PREBUILT TABLE استفاده می شود، همچنین برای پارتیشن بندی و تغییر ساختار جدول مبنا، می توان جدول را ابتدا ایجاد کرد و سپس با این روش به MV مورد نظر تخصیص داد.
create table pre_usef as select file#,name from bl1;
CREATE MATERIALIZED VIEW pre_usef on PREBUILT TABLE REFRESH FORCE AS select file#,name from bl1;
نکته: در این روش با حذف mv، جدول مربوط به آن حذف نمی شود.
REFRESH INTERVAL
چه زمانی بروزرسانی انجام شود؟ در این قسمت به این سوال پاسخ داده می شود. به چهار طریق می توان در مورد بازه زمانی بروزرسانی MVها نظر داد(البته START WITH هم زیرمجموعه ON DEMAND محسوب می شود):
1. ON DEMAND: اگر تصمیم بر بروزرسانی به صورت دستی باشد، باید از عبارت ON DEMAND استفاده کرد(این عبارت در مقابل عبارت ON COMMIT قرار دارد.) پس زمان بروزرسانی، باید به صورت دستی مدیریت شود(می توان از job هم کمک گرفت). ON DEMAND، انتخاب پیش فرض بانک برای زمان بروزرسانی می باشد به عبارتی دیگر دو دستور زیر با یکدیگر یکسانند:
SQL> CREATE MATERIALIZED VIEW mv_tbl4 AS select file#,name from tbl1;
SQL> CREATE MATERIALIZED VIEW mv_tbl4 REFRESH ON DEMAND AS select file#,name from tbl1;
در صورت انتخاب این روش، می توان از پروسیجرهای زیر برای بروزرسانی استفاده کرد:
DBMS_MVIEW.REFRESH
DBMS_MVIEW.REFRESH_ALL_MVIEWS
DBMS_MVIEW.REFRESH_DEPENDENT
2.ON COMMIT : این عبارت سبب می شود تا با هر commit، MV هم بروزرسانی شود این روش سبب کندی در عملیات commit خواهد شد و به همین دلیل به ندرت مورد استفاده قرار می گیرد. همچنین این شیوه بروزرسانی، برخلاف دیگر روشها با dblink سازگاری ندارد و آن را پشتیبانی نمی کند به مثال زیر توجه کنید:
CREATE MATERIALIZED VIEW mv_tbl4 REFRESH ON COMMIT AS select file#,name from tbl1;
select count(*) from mv_tbl4; ==>6
insert into tbl1 values(‘new’,10); commit;
select count(*) from mv_tbl4; ==>7
3.START WITH : با استفاده از این عبارت می توان ساعت شروع و بازه زمانی تکرار را برای بروزرسانی مشخص کرد در این روش، بصورت اتوماتیک یک job توسط اوراکل تعریف می شود که این job را می توان در ویوی dba_jobs مشاهده کرد دستور ساخت MV با استفاده از START WITH به صورت زیر می باشد:
CREATE MATERIALIZED VIEW mv_tbl4 REFRESH START WITH to_date(’23-Nov-2016 09:28:30 PM’,’dd-Mon-yyyy HH:MI:SS AM’) NEXT sysdate + 1/1440 AS select file#,name from tbl1;
عدد 1/1440 به معنی یک دقیقه می باشد. همانطور که در مثال قبلی دیده شد، در هنگام استفاده ازSTART WITH می توان به جای تاریخ دقیق، از تابع sysdate کمک گرفت به طور مثال، دستور زیر مشخص می کند که تاریخ اولین بروزرسانی برابر با یک دقیقه بعد ایجاد MV باشد و تاریخ بروزرسانی های بعدی هم هر دقیقه یکبار باشد:
CREATE MATERIALIZED VIEW mv_tbl5 REFRESH START WITH sysdate + 1/1440 NEXT sysdate + 1/1440 AS select file#,name from tbl1@hozhabr;
بلافاصله بعد از اجرای این دستور، jobای به صورت خودکار از طریق dbms_job ایجاد می شود:
SQL> select job,what from dba_jobs where what like ‘%MV_TBL5%’ ;
JOB WHAT
———- ———————-
4 dbms_refresh.refresh(‘”USEF”.”MV_TBL5″‘);
نکته: همانطور که گفته شد، به جای تعیین تاریخ دقیق، می توان از تابع sysdate در هنگام تعریف job کمک گرفت:
sysdate + 1 ==> یک روز بعد
sysdate + 1/24 ==>یک ساعت بعد
sysdate + 1/1440 ==>یک دقیقه بعد
sysdate + 1/86400 ==>یک ثانیه بعد
البته نیازی به بخاطر سپردن این ساختار نیست بلکه می توان از دستور زیر کمک گرفت:
select sysdate + 1/1440,sysdate from dual; ==> 2016/11/23 21:36:48 , 2016/11/23 21:35:48
4. NEVER REFRESHا: MVای که با این روش ساخته می شود، امکان بروزرسانی ندارد. این کار از طریق دستور alter هم قابل انجام است:
ALTER MATERIALIZED VIEW mv1 NEVER REFRESH;
Refresh method
1.PRIMARY KEY: به صورت پیش فرض، بروزرسانی mv بر اساس primary key انجام می شود(نه بر اساس rowid) و با سازماندهی مجدد جدول مبنا و تغییر rowid، نیازی به بازسازی mv نخواهد بود. این عبارت معمولا در جلوی عبارت مربوط به refresh type قرار می گیرد:
CREATE MATERIALIZED VIEW MV2 REFRESH FAST WITH PRIMARY KEY ON DEMAND AS
select * from ag1;
2.ROWID: در صورتی که بخواهیم بروزرسانی بر اساس rowid انجام بگیرد، باید از عبارت ROWIDدر کنار refresh type استفاده کنیم همچنین در این صورت باید MLOGای که بر روی جدول مبنا ساخته می شود، از نوع rowid باشد که اگر نباشد، خطای زیر رخ می دهد:
ORA-12032: cannot use rowid column from materialized view log on “USEF”.”AG1″
معمولا توصیه می شود در صورتی که تمامی ستونهای مربوط به primary key توسط mv مربوطه مورد استفاده قرار نمی گیرند از روش بروزرسانی rowid استفاده شود. همانطور که قبلا گفته شد، در صورت استفاده از Rowid materialized view، اگر جدول مبنا سازماندهی مجدد شود، mv نیاز به یکبار بروزرسانی کامل خواهد داشت. مثال زیر را در نظر بگیرید:
CREATE MATERIALIZED VIEW MV2 REFRESH FAST WITH ROWID ON DEMAND AS select * from ag1;
برای انجام تست، ابتدا ag1 را سازماندهی مجدد می کنیم:
SQL> alter table ag1 move;
SQL> update ag1 set b=10 where b=3;
با بروزرسانی mv2 خواهیم یافت که سازماندهی مجدد سبب ایجاد اختلال در بروزرسانی شده است:
SQL> exec dbms_mview.refresh(‘MV2′,’f’);
ORA-12034: materialized view log on “USEF”.”AG1″ younger than last refresh
این در صورتی است که با استفاده از primary key، این مشکل ایجاد نخواهد شد و بروزرسانی با موفقیت انجام می شود:
CREATE MATERIALIZED VIEW MV2 REFRESH FAST WITH PRIMARY KEY ON DEMAND AS
select * from ag1;
SQL> update ag1 set b=10 where b=3;
SQL> alter table ag1 move;
SQL> exec dbms_mview.refresh(‘MV2′,’f’);
PL/SQL procedure successfully completed
استفاده از Rowid materialized view امروزه چندان مرسوم نیست و بیشتر برای سازگاری با گذشته، این ویژگی هنوز موجود است.
Materialized View Logs
در زمان ایجاد materialized view اگر از روش بروزرسانی fast برای بهنگام سازی MV استفاده شود، باید بر روی جدول مبنا(جدولی که از روی آن MV ساخته می شود) materialized view log ایجاد شود و در صورت عدم ایجاد MLOG ، امکان ساخت MV به روش بروزرسانیfast وجود نخواهد داشت. MLOG جدولی است که آخرین تغییرات جدول مبنا را از زمان اخرین بروزرسانی MV در خود ثبت می کند و با به هنگام شدن materialized view تغییرات بهنگام شده از این جدول حذف می شوند. MLOG بر روی جدول مبنا با ساختار MLOG$_detailTableID ساخته می شود(detailTableID توسط سیستم ایجاد می شود و معمولا شبیه به اسم جدول مبنا می باشد) همچنین هر جدول در هر لحظه تنها می تواند یک MLOG داشته باشد.
در ادامه مثالی از ایجاد MLOG بر روی جدول tbl1 آورده شده است:
alter table tbl1 add primary key(file#);
create materialized view log on tbl1;
با دستور بالا جدولی با عنوان mlog$_tbl1 ساخته می شود که ساختار ان چنین است:
SQL> desc mlog$_tbl1
Name Type Nullable Default Comments
————— ———– ——– ——- ——–
FILE# NUMBER Y
SNAPTIME$$ DATE Y
DMLTYPE$$ VARCHAR2(1) Y
OLD_NEW$$ VARCHAR2(1) Y
CHANGE_VECTOR$$ RAW(255) Y
XID$$ NUMBER Y
ستون FILE# در این جدول به primary key جدول مبنا اشاره دارد. همچنین ساختار ایجاد MLOG به صورت زیر می باشد:
CREATE MATERIALIZED VIEW LOG ON <schema.table_name>
PCTFREE <integer>
PCTUSED <integer>
TABLESPACE <tablespace_name>
<LOGGING | NOLOGGING>
<CACHE | NOCACHE>
<NOPARALLEL | PARALLEL <integer>>
<table_partitioning_clause>
WITH <OBJECT | PRIMARY KEY | ROWID | SEQUENCE | (column_list)>
[<INCLUDING | EXCLUDING> NEW VALUES];
عبارت WITH PRIMARY KEY
استفاده از این عبارت در هنگام ساخت MLOG سبب می شود تا ستونی با اسم ستون کلید اصلی در MLOG ایجاد شود که متناظر با جدول مبنا مقدار می گیرد. این گزینه به صورت پیش فرض در هنگام ایجاد MLOG انتخاب می شود:
create materialized view log on tbl1 WITH PRIMARY KEY ;
عبارت WITH ROWID
این عبارت سبب می شود تا ستونی با عنوان M_ROW$$ به جدول MLOG اضافه شود که مشخصات rowid رکوردهای تغییر یافته را ذخیره می کند. البته عموما زمانی که جدول مبنا PK نداشته باشد، این ویژگی کاربرد دارد. همچنین در زمان استفاده از join و aggregate استفاده از rowid ضروری می باشد.
create materialized view log on tbl1 WITH ROWID ;
البته می توان هر دو عبارت ROWID و PRIMARY KEY را با هم در دستور استفاده کرد:
create materialized view log on tbl1 WITH ROWID, PRIMARY KEY ;
عبارت WITH SEQUENCE
با این عبارت ستونی به نام SEQUENCE$$ به MLOG اضافه می شود که تریبت انجام عملیات DMLای را بر روی جداول مختلف نشان می دهد به مثال زیر توجه کنید:
sequence$$=1233242
insert into ag1 values(220,10,4);
sequence$$=1233243
insert into ag2 values(65,9,6);
حال با اجرای دستور dmlای دیگر بر روی جدول اول، عدد مربوط به sequence افزایش پیدا می کند:
insert into ag1 values(88,52,44);
sequence$$= 1233245
پس با این ستون از MLOG، می توان ترتیب دقیق عملیات DMLای را بر روی جدولهای مختلف مشخص کرد.
در صورت انجام دستورات DMLای بر روی چند جدول به صورت ترکیبی آن هم در یک تراکنش، استفاده از sqequnce لازم و ضروری است(هر چند نگارنده با تلاش بسیار، موفق به پیاده سازی سناریویی برای این مورد نشده است.)
در صورتی که استفاده از sequence لازم باشد و از آن استفاده نشود، با اجرای پروسیجر explain_mview خواهیم دید که قابلیت REFRESH_FAST_AFTER_ANY_DML پشتیانی نمی شود(N).
عبارتWITH Column List
در صورتی که بخواهیم مقادیر بعضی از ستونها هم در MLOG ذخیره شوند، می توانیم بدین شیوه عمل کنیم:
create materialized view log on tbl1 WITH PRIMARY KEY (name);
البته اگر از WITH PRIMARY KEY استفاده شده باشد، نمی توان از ستون مربوط به PK استفاده کرد.
عبارت INCLUDING NEW VALUES
با این گزینه می توان مقادیر جدید و قدیم رکوردها را با هم در MLOG داشت. زمانی که MV از توابع تجمیعی استفاده می کند برای بروزرسانی به صورت fast refresh، باید از این عبارت هم استفاده شود.
عبارتINCLUDING به صورت پیش فرض مورد استفاده قرار نمی گیرد و مقدار پیش فرض در ساخت MLOG عبارت EXCLUDING می باشد که مانع ذخیره هر دو مقدار با هم می شود.
دو مثال زیر، این نکته را نشان می دهد:
مثال اول(INCLUDING NEW VALUES):
CREATE MATERIALIZED VIEW LOG ON USEF.TBL_PART with primary key(YEAR,AMOUNT_SOLD) INCLUDING NEW VALUES;
INSERT INTO tbl_part VALUES(118,2002,1,3, 9000);
commit;
update tbl_part set amount_sold=800 where year=2002;
commit;
select * from mlog$_tbl_part;

مثال دوم(INCLUDING NEW VALUES):
CREATE MATERIALIZED VIEW LOG ON USEF.TBL_PART with primary key(YEAR,AMOUNT_SOLD) EXCLUDING NEW VALUES;
INSERT INTO tbl_part VALUES(118,2002,1,3, 9000);
commit;
update tbl_part set amount_sold=800 where year=2002;
commit;
select * from mlog$_tbl_part;

عبارت LOGGING/NOLOGGING
تغییرات مربوط به MLOG باید در logهای بانک اطلاعاتی ثبت شوند یا خیر؟!!
عبارت CACHE/NOCACHE
در صورتی که دسترسی به MLOG به کررات صورت می گیرد، بهتر است اجازه داد تا MLOG هم از بافرکش استفاده کند.
- در مثال زیر سعی شده تا اثر هر کدام از عبارت های توضیح داده شده، به صورت واضح تری بیان شود.
create table ag1 (a number primary key, b number,c number);
insert into ag1 values(1,2,3);
commit;
قضد ما در این مثال، ایجاد MLOGای مناسب برای mv زیر می باشد(به صورت آزمون و خطا):
CREATE MATERIALIZED VIEW mv1 REFRESH FAST ON DEMAND AS SELECT a,b,sum(a+b) FROM ag1 GROUP BY a,b;
در ابتدا بر روی جدول ag1، MLOGای را بدون داشتن هیچ پارامتری ایجاد می کنیم:
CREATE MATERIALIZED VIEW LOG ON ag1;
با اجرای دستور ساخت mv، با خطای زیر مواجه می شویم:
ORA-12032: cannot use rowid column from materialized view log on “USEF”.”AG1″
خطای مذکور نشان می دهد که نیاز است بر روی جدول مبنا، MLOG را با استفاده از rowid ایجاد کرد(به دلیل استفاده از توابع تجمیعی در پرس و جو)، پس MLOG را دوباره با افزودن پارامتر rowid ایجاد می کنیم:
drop MATERIALIZED VIEW LOG ON ag1;
CREATE MATERIALIZED VIEW LOG ON ag1 WITH ROWID;
با اجرای مجدد دستور ساخت MV، با خطای زیر مواجه می شویم:
ORA-32401: materialized view log on “USEF”.”AG1″ does not have new values
این خطا می گوید به دلیل استفاده از توابع تجمیعی، باید از عبارت INCLUDING NEW VALUE هم استفاده شود پس MLOG را دوباره ایجاد می کنیم:
drop MATERIALIZED VIEW LOG ON ag1;
CREATE MATERIALIZED VIEW LOG ON ag1 WITH ROWID INCLUDING NEW VALUES;
و باز هم خطایی دیگر:
ORA-12033: cannot use filter columns from materialized view log on “USEF”.”AG1″
که در نهایت با ایجاد MLOG به صورت زیر، مشکل حل خواهد شد:
drop MATERIALIZED VIEW LOG ON ag1;
CREATE MATERIALIZED VIEW LOG ON ag1 WITH ROWID(a,b,c) INCLUDING NEW VALUES;
نکات :
– جدولی که MLOG بر روی ان ایجاد شده است، نمی تواند online redefinition بر روی آن انجام شود.
– ستونهای جدول MLOG را نمی توان با دستور alter حذف کرد(و یا ستون دیگری به آن اضافه کرد.)
حذف محتویات MLOG
حذف محتویات MLOG می تواند به صورت دستی و یا خودکار انجام شود. معمولا بعد از بروزرسانی MV مربوطه، اطلاعات MLOG به صورت خودکار پاک می شود ولی در صورتی که حذف اطلاعات MLOG پرفورمنس لازم را ندارد، می توان حذف اطلاعات را به تاخیر انداخت و به صورت دستی این کار را انجام داد.
نکته: در صورت وجود دو mv بر روی یک جدول که به صورت fast بروز می شوند، اطلاعات MLOG مربوط به جدول مبنا باقی خواهد ماند تا زمانی که هر دو mv بروز رسانی شوند.
در هنگام ساخت MLOG می توان با افزودن عبارت purge، محتویات MLOG در یک بازه زمانی منظمی پاک کرد. همچنین می توان با دستور زیر، اطلاعات مربوط به MLOG را به صورت دستی پاک کرد:
execute DBMS_MVIEW.PURGE_LOG( master => ‘AG1’, num => 10, flag => ‘delete’ ) ;
برای مشاهده روال پاک شدن MLOGها، می توان از ستونهای purge_deferred و purge_asynchronous مربوط به ویوی dba_mview_logs استفاده کرد.
در زیر نمونه ای از تریس مربوط به پاک شدن خودکار محتویات MLOG در هنگام بروزرسانی MV آورده شده است.
PARSING IN CURSOR #139698603816280 len=201 dep=1 uid=0 oct=6 lid=0 tim=13302054160618 hv=2386084879 ad=’31cdd4f50′ sqlid=’4g82vtf73jj0g’
update “USEF”.”MLOG$_AG1″ set snaptime$$ = :1 where rowid in (select rowid from “USEF”.”MLOG$_AG1″ AS OF SNAPSHOT (:2) log$ where snaptime$$ > to_date(‘2100-01-01:00:00:00′,’YYYY-MM-DD:HH24:MI:SS’))
fast refresh و توابع تجمیعی
همانطور که قبلا آورده شد، بروزرسانی از نوع fast refresh، توابع تجمیعی و join را هم پشتیبانی می کند و اگر دستورات DMLای از قبیل INSERT، UPDATE، DELETEبر روی جدول مبنا انجام شوند، از طریق fast refresh، تغییرات بر روی این نوع از mvها هم اعمال می شوند.
در صورت استفاده توامان fast refresh و توابع تجمیعی، باید شرایطی رعایت شود تا همه نوع تغییرات بتوانند بر روی MVها قابل اعمال باشند، به طور مثال اگر عبارت sum() را بدون استفاده از count() در دستور به کار ببریم، قابلیت REFRESH_FAST_AFTER_ANY_DML را پشتیبانی نمی کند. جدول زیر مشخص می کند که در صورت استفاده از کدام تابع تجمیعی، استفاده از چه توایع تجمیعی دیگری اجباری و یا اختیاری(امکان پذیر) خواهد بود:
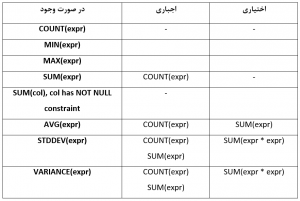
MV تجمیعی محدودیتهای زیادی دارد که در ادامه چند مورد از آن آورده شده است:
- MLOG باید شامل همه ستونهایی حاضر در MV باشد.
create materialized view log on ag1 with ROWID,sequence INCLUDING NEW VALUES;
CREATE MATERIALIZED VIEW MV2 REFRESH fast ON DEMAND AS select sum(b),count(*),count(B) from ag1;
ORA-12033: cannot use filter columns from materialized view log on “USEF”.”AG1″
- عبارت ROWID هم باید در MLOG موجود باشد.
create materialized view log on ag1 with sequence INCLUDING NEW VALUES;
ORA-12032: cannot use rowid column from materialized view log on “USEF”.”AG1″
- استفاده از عبارت INCLUDING NEW VALUES در ایجاد MLOG ها ضروری می باشد.
create materialized view log on ag1 with rowid(a,b) ,sequence;
ORA-32401: materialized view log on “USEF”.”AG1″ does not have new values
- اگر DML ترکیبی بین جداول انجام می شود، باید از SEQUENCE هم استفاده شود(در MLOG منظور است).
- طبق جدولی که آورده شد، عبارت COUNT(*) باید در لیست Select استفاده شود(در هنگام ساخت mv).
exec dbms_mview.refresh(‘MV2′,’f’);
ORA-32314: REFRESH FAST of “USEF”.”MV2″ unsupported after deletes/updates
- دستور select باید شامل همه ستونهای حاضر در GROUP BY باشد.
CREATE MATERIALIZED VIEW MV2 REFRESH fast ON DEMAND AS select sum(b) from ag1 group by c;
ORA-12015: cannot create a fast refresh materialized view from a complex query
- استفاده از توابع max و min سبب می شود تا بعضی از دستورات DMLای پشتیبانی نشوند(REFRESH_FAST_AFTER_ANY_DML) و تنها DML insert قابل انجام باشد.
update ag1 set b=10 where b=3;
exec dbms_mview.refresh(‘MV2′,’F’);
ORA-32314: REFRESH FAST of “USEF”.”MV2″ unsupported after deletes/updates
fast refresh و join MV
برای ایجاد این نوع از mvها، باید دو نکته زیر را در نظر گرفت:
- باید بر روی جداول مورد استفاده، MLOGای با استفاده از rowid ساخت:
create table tbl1 as select name,file# from v$datafile;
create table tbl2 as select d.TS#,l.name,file# from v$tablespace l , v$datafile d where d.TS#=l.TS#;
create materialized view log on tbl1 WITH ROWID ;
create materialized view log on tbl2 WITH ROWID ;
- در لیست Select، rowid هر کدام از جداول هم باید ذکر شوند:
create materialized view mv_tbl refresh fast on demand as select a.rowid ar,b.rowid br,a.name an,b.name bn from tbl1 a,tbl2 b where a.file#=b.file#;
مثالی دیگر از ایجاد join mv با روش بروزرسانی fast:
create materialized view log on ag1 with ROWID(a,b),SEQUENCE INCLUDING NEW VALUES;
create materialized view log on ag2 with ROWID(a,b) ,SEQUENCE INCLUDING NEW VALUES;
CREATE MATERIALIZED VIEW MV3 REFRESH fast ON DEMAND AS
select l.rowid d,g.rowid gg ,l.a,l.b from ag1@amad_test l ,ag2@amad_test g where l.a=g.a ;
insert into ag1 values(21,10,4);
insert into ag2 values(21,10,4);
commit;
execute dbms_mview.refresh( list => ‘USEF.MV2’, method => ‘F’ );
در تریس مربوط به این نوع از بروزرسانی می بینیم:
PARSING IN CURSOR #140323767684048 len=453 dep=1 uid=103 oct=2 lid=103 tim=13303152424596 hv=2929801197 ad=’32f371cf8′ sqlid=’7tymzqara2dzd’
/* MV_REFRESH (INS) */ INSERT /*+ NOAPPEND */ INTO “USEF”.”MV3″ SELECT /*+ NO_MERGE(“JV$”) */ “MAS$1″.ROWID,”JV$”.”RID$”,”MAS$1″.”A”,”MAS$1″.”B” FROM ( SELECT “MAS$”.”ROWID” “RID$” , “MAS$”.* FROM “USEF”.”AG2″@”AMAD_TEST” “MAS$” WHERE ROWID IN (SELECT /*+ HASH_SJ */ CHARTOROWID(“MAS$”.”M_ROW$$”) RID$ FROM “USEF”.”MLOG$_AG2″@”AMAD_TEST” “MAS$” WHERE “MAS$”.SNAPTIME$$ > :B_ST0 )) “JV$”, “AG1″@”AMAD_TEST” “MAS$1” WHERE “MAS$1″.”A”=”JV$”.”A”
PARSING IN CURSOR #140323767846656 len=240 dep=1 uid=103 oct=7 lid=103 tim=13303152500028 hv=2203365457 ad=’31683dcd0′ sqlid=’7z2mzcu1p9c2j’
/* MV_REFRESH (DEL) */ DELETE FROM “USEF”.”MV3″ SNA$ WHERE “D” IN (SELECT /*+ NO_MERGE HASH_SJ */ * FROM (SELECT CHARTOROWID(“MAS$”.”M_ROW$$”) RID$ FROM “USEF”.”MLOG$_AG1″@”AMAD_TEST” “MAS$” WHERE “MAS$”.SNAPTIME$$ > :B_ST1 )MAS$)
PARSING IN CURSOR #140323767846656 len=449 dep=1 uid=103 oct=2 lid=103 tim=13303152511828 hv=2872450373 ad=’e5c6a8d0′ sqlid=’dqg6hvkpmc7a5′
/* MV_REFRESH (INS) */ INSERT /*+ NOAPPEND */ INTO “USEF”.”MV3″ SELECT /*+ NO_MERGE(“JV$”) */ “JV$”.”RID$”,”MAS$0″.ROWID,”JV$”.”A”,”JV$”.”B” FROM ( SELECT “MAS$”.”ROWID” “RID$” , “MAS$”.* FROM “USEF”.”AG1″@”AMAD_TEST” “MAS$” WHERE ROWID IN (SELECT /*+ HASH_SJ */ CHARTOROWID(“MAS$”.”M_ROW$$”) RID$ FROM “USEF”.”MLOG$_AG1″@”AMAD_TEST” “MAS$” WHERE “MAS$”.SNAPTIME$$ > :B_ST1 )) “JV$”, “AG2″@”AMAD_TEST” “MAS$0” WHERE “JV$”.”A”=”MAS$0″.”A”
نکته: برای افزایش کارایی این نوع از mvها، معمولا توصیه می شود که بر روی ستون rowid، ایندکس گذاری صورت بگیرد:
create index index_rowid1 on mv_tbl(br);
create index index_rowid2 on mv_tbl(ar);
MV تودرتو
mv را می توان از روی mv دیگر ایجاد کرد که به آن mv تو در تو می گویند(البته مثال زیر چندان کاربردی نیست و تنها چگونگی انجام این کار را نشان می دهد)
CREATE MATERIALIZED VIEW MV1 REFRESH FAST ON DEMAND AS
select b,sum(b),count(*),count(*) from ag1 group by b;
alter table mv1 add primary key(b);
create materialized view log on mv1 with ROWID(b),sequence INCLUDING NEW VALUES;
CREATE MATERIALIZED VIEW MV2 REFRESH FAST ON DEMAND AS select count(*) from mv1;
با دستور زیر، ابتدا mv1 بروز می شود و سپس بروزرسانی برای mv2 انجام می شود:
exec dbms_mview.refresh(‘MV2′,’F’,nested => TRUE);
حتی اگر mv2 به صورت complete refresh ساخته شده باشد، باز می توان از دستور بالا برای بروزرسانی استفاده کرد.
ایندکس گذاری MVها
دو نوع ایندکس بر روی MVها قابل ایجاد می باشد:
- ایندکسهای سیستمی: زمانی که MV ایجاد می شود، بر روی primary key جدول مربوط به MV، به صورت خودکار ایندکسی ساخته خواهد شد:
SQL> CREATE MATERIALIZED VIEW mv_tbl3 AS select file#,name from tbl1;
SQL> select index_name,uniqueness from dba_indexes l where table_name=’MV_TBL3′;
INDEX_NAME UNIQUENESS
————— ———–
SYS_C0010804 UNIQUE
- ایندکسهای دستی: همانند همه جداول، بر روی جدول مربوط به MV هم می توان به صورت دستی ایندکس ایجاد کرد:
SQL>create index usef.manul_indx on mv_TBL3(name);
با اضافه کردن ایندکس فوق، تعداد ایندکسهای موجود بر روی این MV به عدد دو خواهد رسید:
SQL> select index_name,uniqueness from dba_indexes l where table_name=’MV_TBL3′;
INDEX_NAME UNIQUENESS
—————————— ———-
SYS_C0010804 UNIQUE
MANUL_INDX NONUNIQUE
با بروزرسانی به شیوه complete، ایندکسها کماکان به حیاتشان ادامه می دهند.
بهینه سازی MV
با استفاده از پروسیجر TUNE_MVIEW، این قابلیت وجود دارد که بتوان ساختار پرس و جوی mv را طوری تغییر داد تا بتوان همه قابلیتهای ممکن را پشتیبانی کند. برای این کار، نیاز است تا دستور ساخت mv مورد نظر را به این پروسیجر داد و شکل بهینه شده آن را در ویوی DBA_TUNE_MVIEW مشاهده کرد. دو بلاک pl/sqlای زیر، هر دو یک خروجی را بر می گردانند منتها در بلاک اول، برای راحتی کار، از متغیر استفاده شده است.
بلاک اول:
declare
tune_var VARCHAR2(30):=’&name’;
begin
DBMS_ADVISOR.TUNE_MVIEW(tune_var, &mv_sql);
end;
بلاک دوم:
declare
tune_var VARCHAR2(30):=’name1′;
begin
DBMS_ADVISOR.TUNE_MVIEW(tune_var, ‘CREATE MATERIALIZED VIEW MV6 REFRESH fast ON demand AS select sum(a) from ag1’);
end;
برای مشاهده نتیجه این بهینه سازی، از دستور زیر استفاده می شود:
select * from DBA_TUNE_MVIEW where task_name=’name1′;

با توجه به این که ساخت mvای از نوع fast refresh محدودیتهایی را به همراه دارد، استفاده از این پروسیجر، کشف این محدویتها را بسیار اسان می کند و شکل بهینه شده دستور را به ما بر می گرداند.
فرض کنید فردی mvای جدیدی را ایجاد کرده است ولی این mv را در جایی استفاده نکرده است، با استفاده از ویژگی QUERY REWRITE، اگر فرد تنها پرس و جوی مورد نظر را اجرا کند، سبب می شود تا ساختار دستور آن، در صورت امکان از mv استفاده کند.
برای این کار نیاز است تا در متن mv مورد نظر، از عبارت ENABLE QUERY REWRITE استفاده کرد و همچنین این ویژگی را در سطح session فعال کرد(query_rewrite_enabled=true).
فرض کنید کاربری mv9 را با دستور زیر ایجاد کرد:
CREATE MATERIALIZED VIEW MV9 REFRESH fast ON DEMAND enable query rewrite AS
select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a ;
حال اگر کاربری دستور زیر را اجرا کند، در صورت امکان از mv در دستور استفاده می شود:
select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a ;
یعنی به جای اجرای پرس و جوی بالا، از فرم بازنویسی شده و پرس و جوی زیر استفاده می شود:
SELECT MV9.D D,MV9.GG GG,MV9.A A,MV9.B B FROM USEF.MV9 MV9;
با گرفتن explain plan دستور اصلی، این نکته ثابت خواهد شد.
با فعال بودن قابلیت بازنویسی، بازنویسی برای mvها به صورت transparent انجام می شود برای کشف این نکته که ایا برای mvای خاصی بازنویسی صورت گرفته است یا خیر، می توان از پروسیجر EXPLAIN_REWRITE استفاده کرد. در صورت عدم بازنویسی، پیام “QSM-01150: query did not rewrit” در ستون MESSAGE دیده خواهد شد. برای استفاده از این پروسیجر، باید با اسکریپت زیر، جدولی با ساختار مورد نیاز ساخت:
@?/rdbms/admin/utlxrw.sql
با بلاک زیر، وضیعت بازنویسی mv بررسی می شود:
CREATE MATERIALIZED VIEW MV9 REFRESH fast ON DEMAND ENABLE QUERY REWRITE AS select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a ;
DECLARE
my_query VARCHAR2(200):= ‘select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a’;
BEGIN
DBMS_MVIEW.EXPLAIN_REWRITE(my_query,’mv9′,’100′);
end;
/
خروجی بازنویسی را می توان در پرس وجوی زیر مشاهده کرد:
SELECT mv_owner,mv_name,message,rewritten_txt,original_cost,rewritten_cost FROM rewrite_table;

شرایط بازنویسی شدن یک mv:
1. باید ویژگی ENABLE QUERY REWRITE در متن mv استفاده شده باشد و یا با دستور زیر این قابلیت را برای mv مورد نظر، ایجاد کرد:
ALTER MATERIALIZED VIEW MV2 ENABLE QUERY REWRITE;
2. Query rewrite در سطح session و یا بانک فعال شده باشد.
alter session set QUERY_REWRITE_ENABLED=true;
اگر این پارامتر به force تنظیم شود، در صورتی که پرس و جوی بازنویسی شده، هزینه(cost) بیشتری از پرس و جوی اصلی داشته باشد، باز هم از پرس و جوی بازنویسی شده استفاده می کند.
3.اگر پارامتر query_rewrite_integrity برابر با enforced تنظیم شده باشد و هم چنین mv به صورت stale باشد(ستون STALENESS از ویوی dba_mviews)، در این صورت، بازنویسی ممکن نخواهد بود. همچنین با تنظیم پارامتر query_rewrite_integrity به TRUSTED و یا STALE_TOLERATED، محدودیتها و سختگیریها کمتر می شود. استفاده از پارامتر STALE_TOLERATED سبب می شود تا در هنگام بازنویسی با داده stale همانند داده بروز برخورد شود.
مثال: فرض کنید mv9 در حالت stale قرار دارد، حال اگر از پرس و جوی مربوطه همراه با پارامترهای مختلف استفاده شود، نتیجه ها هم متفاوت خواهد بود:
SQL> set autotrace traceonly explain
SQL> alter system set query_rewrite_integrity=enforced ;
select count(*) from (select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a )
5 ==>یعنی همه اطلاعات را نشان می دهد چون به جدول اصلی رجوع می کند
select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a ;
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
——————————————————————
| 0 | SELECT STATEMENT | |3 |54 |3 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 3 | 54 |3 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| AG1|4 | 36 | 3 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN| SYS_C0010972 | 1 | 9 |0 (0)| 00:00:01 |
حال اگر پارامتر query_rewrite_integrity را به STALE_TOLERATED تنظیم کنیم، جواب خروجی تغییر می کند و همچنین explain plan آن عوض می شود:
alter system set query_rewrite_integrity=STALE_TOLERATED;
select count(*) from (select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a )
3 ==>یعنی همه اطلاعات را نشان نمی دهد
select l.rowid d,g.rowid gg ,l.a,l.b from ag1 l ,ag2 g where l.a=g.a ;
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time|
——————————————————————–
| 0 | SELECT STATEMENT | |3 |78 | 3 (0)| 00:00:01 |
| 1 | MAT_VIEW REWRITE ACCESS FULL| MV9 | 3 |78 |3(0)| 00:00:01 |
حذف MV
با دستور زیر می توان mv را حذف کرد:
drop MATERIALIZED VIEW MV2;
در صورتی که mv مورد نظر به صورت prebuilt ایجاد شده باشد، تنها mv حذف خواهد شد و جدول مربوطه باقی می ماند.
چند پرس و جو برای مانیتورینگ
پرس و جوی اول: مدت زمانی که یک mv به صورت fast و یا complete اجرا شده است را می توان بر اساس ثانیه با پرس و جوی زیر مشخص کرد:
SELECT owner,mview_name, last_refresh_date start_refresh, fullrefreshtim complete_time, increfreshtim fast_time FROM dba_mview_analysis l order by l.last_refresh_date desc;
پرس و جوی زیر زمان اتمام mvها را هم مشخص می کند:
SELECT mview_name,last_refresh_date “START_TIME”, CASE WHEN fullrefreshtim <> 0 THEN LAST_REFRESH_DATE + fullrefreshtim/60/60/24 WHEN increfreshtim <> 0 THEN LAST_REFRESH_DATE + increfreshtim/60/60/24 ELSE LAST_REFRESH_DATE END “END_TIME”, fullrefreshtim complete_time,increfreshtim “fast_time” FROM all_mview_analysis order by last_refresh_date desc;
پرس و جوی دوم: تعیین جدول مبنای مربوط به هر mv:
select OWNER, NAME, MASTER_OWNER, MASTER, LAST_REFRESH from DBA_SNAPSHOT_REFRESH_TIMES ;
پرس و جوی سوم: کدام یک از mvها در حال بروزرسانی می باشند:
select o.owner, o.object_name mview, username, s.sid from v$lock l, dba_objects o, v$session s where o.object_id=l.id1 and l.type=’JI’ and l.lmode=6 and s.sid=l.sid and o.object_type=’TABLE’;
همچنین در جدول زیر، لیستی از ویوهای مرتبط با mv آورده شده است:
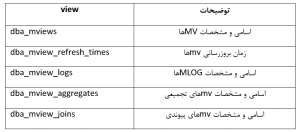
نکات مرتبط با MVها
1.عبارت ORDER BY در هنگام ساخت mv قابل استفاده می باشد ولی در بروزرسانی ها موثر نخواهد بود.
2.در صورتی که مقدار پارامتر Open_links به صفر تغییر کند و یا کمتر از تعداد db_linkهای در حال استفاده باشد، با خطای زیر مواجه می شویم:
ORA-02020: too many database links in use
3.پارامتر Job_queue_processes باید به تعداد jobای که قرار است به طور همزمان اجرا شوند، باشد.
4.دستور analyze برای mv باید با فرمت زیر انجام شود:
analyze table mv3 compute statistics;
5.فیلد STALENESS در dba_mviews وضیعت جاری mv را نشان می دهد که یکی از مقادیر زیر را خواهد داشت:
UNDEFINED: در صورتی که از dblink در یک mv استفاده شود، وضیعت mv مورد نظر برابر با تعریف نشده خواهد بود.
UNUSABLE: عملیاتی همچون truncate بر روی یک mv، سبب می شوند تا mv مورد نظر، غیرقابل استفاده شود در این حالت برای fresh شدن mv، باید بروزرسانی کامل صورت بگیرد.
STALE : داده های mv بروز نیستند.
NEEDS_COMPILE: مmv مورد نظر نیاز به کامپایل دارد.
COMPILATION_ERROR :با عملیاتی همچون حذف جدول مبنا، حذف یکی از فیلدهای مرجع mv و یا تغییر نوع داده فیلد مرجع mv، mvهای مربوطه در این وضیعت قرار می گیرند.
6.عبارت FOR UPDATE در هنگام ساخت mv سبب می شود تا بتوان در جدول مربوط به mv، اطلاعاتی را بروز کرد:
CREATE MATERIALIZED VIEW USEF.MV1
BUILD IMMEDIATE
REFRESH FORCE
ON DEMAND
FOR UPDATE
ENABLE QUERY REWRITE
AS
7.برای افزودن CONSTRAINT به mv، می توان از دستور زیر استفاده کرد:
alter table mv2 add CONSTRAINT usef_CONSTRAINT CHECK(a<=50);
8.هر چند این کار با ALTER MATERIALIZED VIEW هم امکان پذیر است:
ALTER MATERIALIZED VIEW mv2 add CONSTRAINT usef_CONSTRAINT CHECK(a<=50);
9.برای مشاهده مشخصات همه constrainهای موجود بر روی mv2، می توان از پرس و جوی زیر استفاده کرد:
select * from dba_constraints l where l.TABLE_NAME=’MV2′
Vahid Yousefzadeh
ارائه خدمات مشاوره ، پشتیبانی و نصب و راه اندازی پایگاه داده اوراکل در سراسر کشور...................... تلفن: 09128110897 ایمیل:vahidusefzadeh@gmail.com