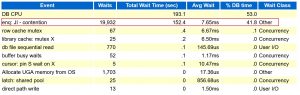
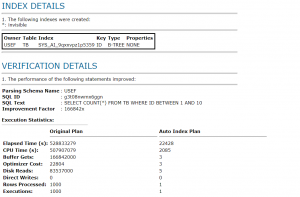
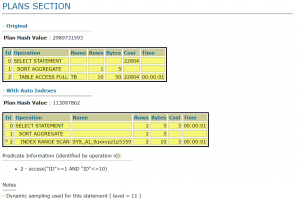
همانطور که می دانید AWR snapshotها در SYSAUX tablespace ذخیره می شوند و تا نسخه 19c نمی توان آنها را در tablespace مجزایی ذخیره کرد. این امکان در نسخه 19c با اضافه شدن پارامتر TABLESPACE_NAME به پروسیجر dbms_workload_repository.modify_snapshot_settings به وجود آمد.
Connected to Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 SQL> desc dbms_workload_repository.modify_snapshot_settings Parameter Type Mode Default? --------------- -------- ---- -------- RETENTION NUMBER IN Y INTERVAL NUMBER IN Y TOPNSQL NUMBER IN Y DBID NUMBER IN Y TABLESPACE_NAME VARCHAR2 IN Y RETENTION NUMBER IN Y INTERVAL NUMBER IN Y TOPNSQL VARCHAR2 IN DBID NUMBER IN Y TABLESPACE_NAME VARCHAR2 IN Y
همچنین اوراکل در نسخه 21c ستون TABLESPACE_NAME را به ویوی awr_cdb_wr_control اضافه کرده است که از طریق آن می توانیم tablespace جاری AWR را مشخص کنیم: