در دیتابیس اوراکل انواع مختلفی از ایندکسها وجود دارند که از آنها به منظور بهبود کارایی دیتابیس استفاده می شود ولی هر کدام دارای کاربرد و ساختار متفاوت هستند. در این متن ایندکس های از نوع BITMAP که فقط در نسخه های ENTERPRISE اوراکل قابل تعریف و استفاده هستند را توضیح می دهیم.
ساختار BITMAP INDEX
زمانی که برای یک ستون از جدول، ایندکس BITMAP تعریف می شود یک ساختمان داده دو بعدی برای آن ستون ایجاد می گردد که تعداد سطرهای آن برابر با تعداد سطرهای جدول و تعداد ستون هایش برابر با تعداد مقادیر DISTINCT در ستون ایندکس گذاری شده خواهد بود. در این ساختمان داده از 0 و 1 برای مشخص نمودن وجود یا عدم وجود مقدارها استفاده می شود.
برای مثال اگر برای ستون GENDER در جدول زیر از BITMAP استفاده کنیم، ساختمان داده ایندکس به شکل زیر خواهد بود:
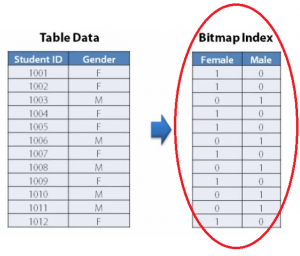
از آنجایی که فقط از 0 و 1 برای مشخص نمودن مقادیر استفاده می شود استفاده از این ساختمان داده سبب صرفه جویی در حافظه می شود. همچنین آرایه های بیتی به راحتی می توانند فشرده و ذخیره شوند.
زمانی که یک QUERY نیازمند استفاده از ایندکس BITMAP می باشد، ساختمان داده BITMAP به سرعت از حالت فشرده خارج شده و در BUFFER CACHE قرار می گیرد. سپس تمام ROWID سطرهای مورد نیاز برای آن QUERY برگردانده می شوند. بنابراین در این ساختمان داده برای هر سطر، یک ROWID نیز ذخیره می شود.
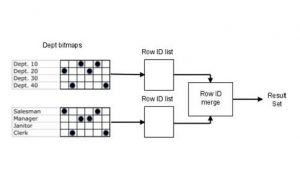
در دیتابیس اوراکل اگر دو یا چند ستون BITMAP در یک جدول داشته باشیم برای QUERYهایی که شامل آن ستون ها می شوند به صورت اتوماتیک ساختمان داده BITMAPها به هم متصل می گردند و از عملیات منطقی بیتی بین آنها استفاده می شود که از لحاظ PERFORMANCE بسیار مناسب خواهد بود.
برای مثال در جدول زیر سه ستون دارای BITMAP هستند بنابران می توان زنانی که متاهل هستند و سن آنها بین 35 تا 49 سال است را با سرعت بالا QUERY نمود زیرا از دستور AND منطقی بین بیت های این BITMAPها استفاده می شود.
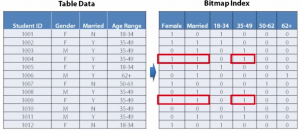
در شکل زیر مشاهده می کنید که ROWIDهای مورد نیاز برای دو ستون مختلف از جدول باهم ادغام می شوند و در پاسخ نهایی QUERY برگردانده می شوند.
چه زمانی از ایندکس BITMAP استفاده کنیم؟
در موارد زیر استفاده از ایندکس های BITMAP سبب بهبود PERFORMANCE می شود:
1.زمانی که داده های یک ستون از جدول دارای LOW CARDINALITY است یعنی داده های تکراری زیادی در آن ستون داریم. پیشنهاد می گردد تعداد مقدارهای DISTINCT حداکثر صد یا چند صد مورد باشند و اینکه تعداد تکرارها خیلی بیشتر از تعداد سطرها باشد در غیر این صورت استفاده از ایندکس های B-TREE به صرفه تر خواهد بود.
برای مثال ستونی که فقط چند رنگ را برای چند میلیون ماشین مشخص می کند و یا ستون جنسیت افراد.
2.در دیتابیس های OLTP یا جدول هایی که عملیات DML روی آنها زیاد انجام می شود بهتر است از ایندکس BITMAP استفاده نگردد زیرا در زمان تغییرات داده ها، بروزرسانی ساختمان داده BITMAP زمانبر و غیر بهینه خواهد بود. بنابراین معمولا در دیتابیس های DATA WAREHOUSE یا جدول های با بروزرسانی کم از BITMAP استفاده می شود.
3.زمانی که در QUERYها از ترکیب چندین ستون که شرایط 1 و 2 را دارند استفاده می شود بهتر است بجای ایندکس ترکیبی B-TREE برای تمام آن ستون ها به صورت مجزا از BITMAP استفاده نمود زیرا نتایج ستون های BITMAP به صورت اتوماتیک با هم ادغام می شوند.
4.برای MATERIALIZED VIEW هایی که در بازه زمانی خارج از پیک کاری بروز رسانی می شوند استفاده از BITMAP مناسب خواهد بود.
5.در QUERYهایی که وجود مقدار NULL را بررسی می کنند می توان از BITMAP استفاده کرد زیرا این مقادیر توسط ایندکس BITMAP قابل دسترسی هستند ولی توسط ایندکسهای از نوع B-TREE قابل دسترس نیستند و عمل FULL TABLE SCAN انجام می شود.
نقاط ضعف BITMAP
در موارد زیر از لحاظ PERFORMANCE استفاده از ایندکسهای دیگر مانند B-TREE به صرفه تر خواهد بود:
1.در دیتابیس اوراکل اگر نیاز باشد یک مقدار از یک ستون که ایندکس BITMAP دارد بروزرسانی شود می بایست تمام سطرهای آن ستون LOCK شوند. بنابراین استفاده از BITMAP برای جدول هایی که تعداد تراکنش متوسط یا زیاد دارند از لحاظ PERFORMANCE به صرفه نیست و باعث مشکلات متعدد می شود.
2.سرعت QUERYهای محدوده ای (مانند عملگر BETWEEN) را نمی توان با ایندکس BITMAP بهبود داد. برای این QUERYها استفاده از ساختمان داده درختی (B-TREE) بهتر خواهد بود.
3.اگر اندازه جدول کوچک باشد دیتابیس اوراکل معمولا بجای استفاده از BITMAP از عمل FULL TABLE SCAN استفاده می کند.
4.برای ستون هایی که به PRIMARY KEY نزدیک هستند فضای حافظه زیادی مورد نیاز خواهد بود و استفاده از BITMAP به صرفه نیست.
یک مثال عملی از کارایی بهتر BITMAP
ساخت جدول با دو ستون همراه با تولید و درج یک میلیون مقدار تصادفی:
SQL> Create table milad.karbaran (shomare number(7), jens varchar2(4));
Table created
SQL>
SQL> Begin
For i in 1..1000000
Loop
Insert into milad.karbaran
values(i, decode(round(dbms_random.value),1,‘MARD’,(decode(round(dbms_random.value), 1, null, ‘ZAN’))));
If mod(i, 100) = 0 then
Commit;
End if;
End loop;
End;
/
PL/SQL procedure successfully completed
SQL>
SQL> select jens,count(*) from karbaran group by jens;
JENS COUNT(*)
—- ———-
MARD 499532
250899
ZAN 249569
SQL>
بنابراین در این جدول، ستون jens دارای CARDINALITY پایین است و با فرض پایین بودن عملیات DML استفاده از ایندکس BITMAP برای QUERYهای شبیه به دستور زیر سبب دستیابی به COST کمتر و سرعت بالاتر می شود:
select count(*) from milad.karbaran t where t.jens=’MARD’;
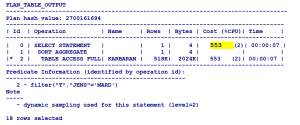
مشاهده COST در حالت FULL TABLE SCAN :
SQL> explain plan for select count(*) from milad.karbaran t where t.jens=’MARD’;
Explained
SQL> select * from table(dbms_xplan.display);
مشاهده COST با استفاده از ایندکس B-TREE:
SQL> create index jens_btreeind on milad.karbaran(jens);
Index created
SQL> explain plan for select /*+ index(karbaran jens_btreeind)*/count(*) from milad.karbaran t where t.jens=’MARD’;
Explained
SQL> select * from table(dbms_xplan.display);
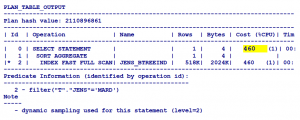
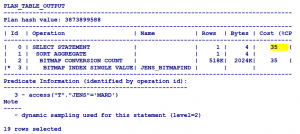
مشاهده COST با استفاده از ایندکس BITMAP:
SQL> drop index jens_btreeind ;
Index dropped
SQL> create bitmap index jens_bitmapind on milad.karbaran(jens);
Index created
SQL> explain plan for select /*+ index(karbaran jens_bitmapind)*/count(*) from milad.karbaran t where t.jens=’MARD’;
Explained
SQL> select * from table(dbms_xplan.display);
عالی بود ممنون
بسیار عالی و روشن بیان فرمودید ممنون
ممنونم بابت تبادل اطلاعات ارزشمندتون , عالی بود.