در مبحث “آشنایی با Clustering Factor در اوراکل” مطالبی را در مورد CLUSTERING_FACTOR ارائه دادیم در این مطلب قصد داریم با چند مثال عملی را در این زمینه ارائه کرده و در پایان، هزینه استفاده از ایندکس را برای هر دو حالت با هم مقایسه خواهیم کرد.
مثال 1(CLUSTERING_FACTOR بد): قصد داریم با اجرای پرس و جوی زیر، اطلاعاتی از جدول badcftable را در خروجی نمایش دهیم:
SQL> Select * from badcftable where code=2;
ساختار جدول badcftable به صورت زیر می باشد:
SQL> desc badcftable;
Name Type
—- ————
CODE NUMBER
NAME VARCHAR2(10)
با این توضیح که جدول badcftable حاوی 100 رکورد و ده بلاک می باشد و در ستون code، اعداد 1 تا 10 هر کدام ده بار تکرار شده اند به طوری که هر بلاک حاوی مقادیر 1 تا 10 می باشد.
نحوه چینش مقادیر ستون code در بلاکهای جدول cftable :

در قطعه کد زیر، با کمک هینت APPEND اطلاعاتی را با ساختار فوق در جدول badcftable درج می کنیم:
SQL> begin
2 for i in 1..10 loop
3 insert /*+APPEND */ into badcftable SELECT level,’abcd’ FROM DUAL CONNECT BY LEVEL <=10;
4 commit;
5 end loop;
6 end;
7 /
PL/SQL procedure successfully completed
دستور زیر نشان می دهد که جدول badcftable حاوی ده بلاک می باشد که در هر بلاک آن، ده رکورد قرار گرفته است:
select count(*), dbms_rowid.rowid_block_number(rowid) as block# from badcftable group by dbms_rowid.rowid_block_number(rowid) order by 2;
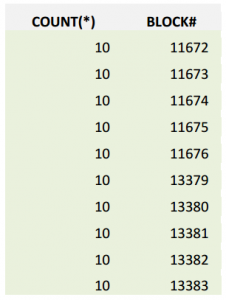
همچنین با دستور زیر می توان مشاهده کرد که عدد شماره دو در چه شماره بلاکهایی ذخیره شده است:
select dbms_rowid.rowid_block_number(rowid) as block# from badcftable where code=2;

همانطور که می بینید، عدد دو در ده بلاک ذخیره شده است. در چنین شرایطی، ایندکس ind1 را بر روی ستون code ایجاد می کنیم.
SQL> create index IND_BADCF on badcftable(code);
Index created
سپس امار مربوط به جدول و ایندکس را بروزرسانی می کنیم:
SQL> exec dbms_stats.gather_table_stats(ownname =>’USEF’ ,tabname =>’BADCFTABLE’ ,cascade => true);
PL/SQL procedure successfully completed
در پایان با دستور زیر، CLUSTERING_FACTOR مربوط به ایندکس ind1 را مشخص می کنیم:
SQL> select owner,index_name,p.CLUSTERING_FACTOR from dba_ind_statistics p where p.INDEX_NAME=’IND_BADCF’;

نکته: در صورتی که تعداد بلاکهای یک جدول کمتر از عدد تعیین شده برای پارامتر db_file_multiblock_read_count باشد، از ایندکس استفاده نخواهد شد از این رو، برای آن که در سنارویوی ما از ایندکس استفاده شود، باید مقدار این پارامتر را به عدد پایین تری تنظیم کنیم:
SQL> alter system set db_file_multiblock_read_count=1;
System altered
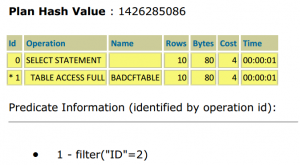
در این شرایط، با مشاهده execution plan پرس و جوی زیر خواهیم دید که ایندکس IND_BADCF به دلیل CLUSTERING_FACTOR بالایی که دارد، توسط optimizer انتخاب نمی شود:
select * from badcftable a where code =2;
مثال 2(CLUSTERING_FACTOR خوب): در این مثال چینش اطلاعات موجود در ستون code را به شکلی تغییر می دهیم که CLUSTERING FACTOR آن به مقدار blocks نزدیکتر باشد تا مقدار num_rows:

همانند مثال قبلی، از هینت append استفاده کرده و اطلاعات را به شیوه فوق، در جدول جدیدی که در ابتدا ایجاد می شود، درج می کنیم:
SQL> create table GOODcftable as select * from cftable where 1=2;
Table created
SQL>begin
for i in 1..10 loop
insert /*+APPEND */ into GOODcftable SELECT i,’abcd’ FROM DUAL CONNECT BY LEVEL <=10;
commit;
end loop;
end;
/
پس از درج این اطلاعات خواهیم دید که در هر بلاک ده رکورد قرار گرفته است:
select count(*), dbms_rowid.rowid_block_number(rowid) as block# from GOODcftable group by dbms_rowid.rowid_block_number(rowid) order by 2;

و هر عدد صرفا در یک بلاک قرار دارد:
select dbms_rowid.rowid_block_number(owed) as block# from GOODcftable where id=2;

با ایجاد ایندکسی بر روی ستون code، خواهیم دید که مقدار CLUSTERING_FACTOR این ایندکس برابر خواهد بود با تعداد بلاکهای جدول GOODcftable:
SQL> create index IND_GODCF on GOODcftable(CODE);
Index created
SQL> exec dbms_stats.gather_table_stats(ownname =>’USEF’ ,tabname =>’GOODCFTABLE’ ,cascade => true);
PL/SQL procedure successfully completed
SQL> select owner,index_name,p.CLUSTERING_FACTOR from dba_ind_statistics p where p.INDEX_NAME=’IND_GODCF’;

در این شرایط، optimizer به جای FULL SCAN کردن جدول GOODcftable،از ایندکس ind2 استفاده می کند.
select * from GOODcftable a where code=2;
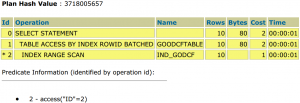
نکته: OPTIMIZER در زمان انتخاب یک ایندکس، به فاکتورهای دیگری نظیر avg_row_len، db_block_size، selectivity و cardinality هم توجه خواهد کرد.
جزییاتی دیگری در مورد دو ایندکس IND_GODCF و IND_BADCF
شرایط دو ایندکس فوق را در نظر بگیرید:
SQL> select index_name,clustering_factor,num_rows from dba_indexes v where index_name in (‘IND_GODCF’,’IND_BADCF’ );
INDEX_NAME CLUSTERING_FACTOR NUM_ROWS
———— —————– ———-
IND_BADCF 100 100
IND_GODCF 10 100
قصد داریم با hintای استفاده از این دو ایندکس را برای پرس و جوهای “مثال قبل” اجبار کنیم و با فعال کردن trace، جزییات بیشتری را در مورد اجرای این دو پرس و جو ببینیم:
—BAD CF INDEX
SQL> select /*+ index(a IND_BADCF ) */ count(name) from BADcftable a where code>=1;
COUNT(NAME)
———–
100
[oracle@Primary ~]$ tkprof /19c/home/log/diag/rdbms/cdb19c/cdb19c/trace/cdb19c_ora_23099.trc sys=no waits=yes
مشاهده قسمتی از خروجی فایل تریس:
select /*+ index(a IND_BADCF ) */ count(name) from BADcftable a where code>=1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
———- ———- ———- —————————————————
1 1 1 SORT AGGREGATE (cr=92 pr=11 pw=0 time=1351 us starts=1)
100 100 100 TABLE ACCESS BY INDEX ROWID BATCHED BADCFTABLE (cr=92 pr=11 pw=0 time=13022 us starts=1 cost=101 size=800 card=100)
100 100 100 INDEX RANGE SCAN IND_BADCF (cr=1 pr=1 pw=0 time=333 us starts=1 cost=1 size=0 card=100)(object id 74046)
برای محاسبه تعداد I/O کافیست تا cr یا همان CONSISTENT READ موجود در خط INDEX RANGE SCAN را از cr موجود در TABLE ACCESS BY INDEX ROWID BATCHED کم کنیم بنابرین تعداد I/O در این حالت برابر خواهد بود با 91.
در شرایطی اجرای پرس و جوی فوق به 91 I/O نیاز دارد که جدول BADCFTABLE تنها ده بلاک دارد!!!
SQL> select blocks from user_tables where table_name=’BADCFTABLE’;
BLOCKS
———-
10
—GOOD CF INDEX
select /*+ index(a IND_GODCF ) */ count(name) from GOODcftable a where code>=1
Rows (1st) Rows (avg) Rows (max) Row Source Operation
———- ———- ———- —————————————————
1 1 1 SORT AGGREGATE (cr=11 pr=11 pw=0 time=1317 us starts=1)
100 100 100 TABLE ACCESS BY INDEX ROWID BATCHED GOODCFTABLE (cr=11 pr=11 pw=0 time=903 us starts=1 cost=11 size=800 card=100)
100 100 100 INDEX RANGE SCAN IND_GODCF (cr=1 pr=1 pw=0 time=467 us starts=1 cost=1 size=0 card=100)(object id 74047)
در این حالت تعداد I/O کمتری خواهیم داشت(10 I/O) و دستور با سرعت بهتری اجرا خواهد شد. جدول GOODCFTABLE صرفا ده بلاک دارد.
SQL> select blocks from user_tables where table_name=’GOODCFTABLE’;
BLOCKS
———-
10
Vahid Yousefzadeh
ارائه خدمات مشاوره ، پشتیبانی و نصب و راه اندازی پایگاه داده اوراکل در سراسر کشور...................... تلفن: 09128110897 ایمیل:vahidusefzadeh@gmail.com