قصد داریم از طریق یکی از ایندکسهای جدول، به تک تک رکوردهای آن جدول دسترسی پیدا کنیم به این صورت که ابتدا آدرس فیزیکی یا همان rowid رکورد را از طریق ایندکس پیدا کرده و سپس با انتقال Data Block حاوی آن رکورد به حافظه، جدول را scan کنیم.
از آنجایی که اطلاعات در ایندکس به صورت “مرتب” ذخیره می شوند، هر چه ترتیب قرار گرفتن رکوردها در جدول مشابه ترتیب قرارگیری keyها در ایندکس باشد، نیاز به I/O کمتری خواهیم داشت و SCAN جدول از طریق ایندکس می تواند با سرعت بیشتری انجام شود.
به عبارتی دیگر اگر در یک Leaf Block پنج index entry موجود باشد، در بهترین حالت هر پنج رکورد متناظر با index entryها، در یک Data Block قرار می گیرند و در بدترین حالت، هرکدام از این رکوردها در یک بلاک مجزا در جدول ذخیره شده اند.
اوراکل کیفیت این چینش را با یک عدد نمایش می دهد که اصطلاحا Clustering Factor نامیده می شود این عدد بیانگر تعداد دفعات سوییچ بین بلاکهای جدول می باشد(در زمان خواندن دیتای جدول از طریق ایندکس).
برای محاسبه مقدار Clustering Factor، اوراکل بررسی می کند که آیا Data Block ارجاع داده شده برای دو index entry پشت سرهم، با هم متفاوت هستند یا خیر؟ در صورت یکسان بودن Data Blockها، Clustering Factor در همان مقدار قبلی اش باقی خواهد ماند و در صورت تفاوت، یک عدد به مقدار Clustering Factor اضافه می شود به عبارتی، با هر سوییچی بین Data Blockها، یک عدد به Clustering Factor افزوده خواهد شد.
بنابرین اگر تمامی رکوردهای موجود در یک leaf block(ایندکس) صرفا در یک data block(جدول) موجود باشند و بر پایه همین قاعده، بین همه leaf blockها و data blockها تناظر یک به یک وجود داشته باشد، مقدارClustering Factor بسیار کاهش پیدا کرده و اصطلاحا ایندکس Clustering Factor خوبی دارد.
dba_indexes.CLUSTERING_FACTOR=dba_tables.blocks
برخلاف قائده فوق، اگر مقدار dba_indexes.CLUSTERING_FACTOR برابر یا نزدیک به تعداد رکوردهای جدول باشد، ایندکس، Clustering Factor خوبی نخواهد داشت.
توجه: در صورتی که جدول حاوی بلاکهای خالی زیادی باشد، به بیانی دقیق تر، اگر تعداد بلاکهای جدول از تعداد رکوردهای آن کمتر باشد قائده ذکر شده برای تشخیص Clustering Factor خوب و بد نقض خواهد شد.
نمونه ای از Clustering Factor خوب و بد
دو مثالی که در ادامه مشاهد خواهید کرد، با فرضیات زیر ارائه خواهند شد:
1.buffer cache در دیتابیس حاضر شامل دو نوع buffer pool می باشد: Default Buffer Pool و Keep Buffer Pool
2.در Default Buffer Pool صرفا یک بافر موجود است و قرار است بلاکهای جدول در زمان فراخوانی به این قسمت از حافظه منتقل شوند(تنها یک جدول در دیتابیس موجود است).
3.بلاکهای مربوط به ایندکس در فضای Keep Buffer Pool قرار می گیرند که فضای این buffer pool بزرگتر از اندازه تنها ایندکس موجود بر روی جدول است و segment دیگری در این فضا قرار ندارد.
نمونه ای از Clustering Factor خوب
شکل زیر نمونه ای از Clustering Factor با performance مناسب را نمایش می دهد زیرا که خواندن کامل جدول از طریق ایندکس، صرفا با چهار I/O(به تعداد بلاکها) قابل انجام خواهد بود(با این فرض که ایندکس قبلا در keep buffer pool قرار گرفته است).
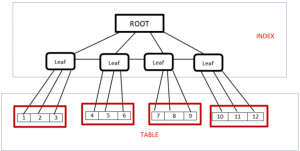
به صورت جزیی تر می توان گفت که در I/O اول، Data Block شماره 1 به حافظه منتقل می شود و با توجه به انکه تمامی رکوردهای موجود در Leaf Node اول در این Data Block موجود هستند، نیاز به هیچ سوییچی بین Data Blockها نخواهد بود و بدون آنکه Clustering Factor افزایش پیدا کند، رکوردهای 1 و 2 و 3 از جدول خوانده خواهند شد(با رجوع به Data Block اول، Clustering Factor برابر با یک خواهد شد).
در ادامه هم با خواندن Leaf Node شماره دو، Data Block دوم بجای Data Block شمار یک به حافظه انتقال داده خواهد شد(با توجه به آنکه Default buffer pool صرفا شامل یک بافر می باشد) و با توجه به آنکه این Data Block همه رکوردهای Leaf Node را پوشش می دهد، صرفا یک عدد Clustering Factor اضافه خواهد شد و الی اخر …
با این سناریو، Clustering Factor ایندکس برابر خواهد بود با تعداد بلاکهای جدول که بیانگر Clustering Factor مناسب می باشد.
نمونه ای از Clustering Factor بد
در تصویر زیر، برای خواندن رکورد شماره 1، باید بلاک شماره 1 به حافظه منتقل شود(I/O اول) و با توجه به آنکه رکوردهای leaf node در یک data block موجود نیستند، برای خواندن رکوردهای شماره 2 و 3 باید بلاک شماره 2 به جای بلاک شماره 1 در حافظه قرار گیرد (I/O دوم) و به همین شکل برای خواندن محتویات رکورد شماره 4 و 5 مجددا باید بلاک شماره یک به حافظه منتقل شود(I/O سوم) و ….
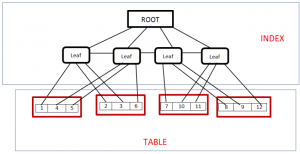
بسیار بدیهی است که خواندن اطلاعات در شکل اول با کارایی بهتری انجام می شود و optimizer هم در هنگام انتخاب plan، باید این مسئله را مدنظر قرار دهد تا در انتخاب plan بهتر، دچار اشتباه نشود.
وحید یوسف زاده
ارائه خدمات مشاوره ، پشتیبانی و نصب و راه اندازی پایگاه داده اوراکل در سراسر کشور...................... تلفن: 09128110897 ایمیل:vahidusefzadeh@gmail.com
مهندس جان
راهکارهایی که یه کلاسترینگ فکتور بد رو تبدیل به کلسترینگ فکتور خوب کنیم؟
مطلب table cached block رو دیدم مفید بود روش های دیگه ای هم هست؟
سلام وقتتون بخیر
مطلبی که در مورد Clustering Factor در سایت موجود است را مطالعه بفرمایید.