اوراکل با ارائه نسخه 10g، تکنولوژی قدرتمندی به نام Data Pump را ارائه کرد با استفاده از این تکنولوژی می توان حجم زیادی از اطلاعات را از دیتابیس استخراج کرد یا از یک بانک به بانک دیگر منتقل نمود.
Data Pump از نظر عملکرد همانند ابزارهای exp/imp قدیمی است ، ولی از نظر روش انجام کار، متفاوت است. exp/imp سنتی مبتنی بر کلاینت هستند در حالی که Data Pump کاملا مبتنی بر سرور پیاده سازی شده است.
Data Pump قابلیتهای فراوان تری نسبت به ابزارهای exp/imp سنتی دارد که تعدادی از آنها را در این قسمت برمی شماریم:
1.بهبود سرعت export/import تا چندین برابر
2.اجرای ابزار به صورت server side و عدم وابستگی به کلاینت(که باعث مدیریت و کارایی بهتر خواهد شد)
3.امکان تغییر تنظیمات در حین اجرای عملیات
4.امکان اجرای عملیات export یا import اطلاعات به صورت parallel processing
5.امکان اجرای مجدد و ادامه عملیات در صورت توقف
6.اجرای عملیات از طریق network
و …
تکنولوژی Data Pump برای انجام عملیات استخراج و بارگذاری اطلاعات از دو پکیج زیر استفاده می کند:
1.DBMS_DATAPUMP : دارای پروسیجرهایی است برای استخراج و بارگذاری محتوای جداول که به آن data pump API نیز گفته می شود.
2.DBMS_METADATA : دارای پروسیجرهایی است برای استخراج و بارگذاری ساختار جداول و متاداده موجود در data dictionary که به آن metadata API نیز گفته می شود.
با توجه به اینکه استفاده از این پکیج ها و پروسیجرها با پیچیدگی هایی همراه است، در کنار data pump دو ابزار با نامهای (expdp (export data pump و (impdp (import data pump ارائه شده است که به ترتیب برای استخراج و بارگذاری داده ها مورد استفاده قرار می گیرند و بصورت command line به کار گیری می شوند.
البته این ابزارها هم برای انجام استخراج و بارگذاری اطلاعات از پکیج های DBMS_DATAPUMP و DBMS_METADATA استفاده می کنند ولی استفاده از آنها به مراتب آسانتر از بکارگیری مستقیم پکیج ها می باشد.
هنگام استفاده از data pump چندین پروسس (مانند master, worker, shadow, …) ایجاد و شروع به کار می کنند. پروسس master اولین و مهمترین پروسس می باشد که با ایجاد یک job عملیات export/import را شروع و کل فرایند را کنترل می کند.
نکته : در طول عملیات export/import ، با ارجاع به نام job می توان آنرا کنترل نمود (مانند توقف عملیات، اجرای مجدد، اضافه نمودن فایل جدید و …)
بطور پیشفرض برای هر کدام از این job ها یک نام به شکل sys_<job type>_<mode>_nn در نظر گرفته می شود که
sys_<job type>_<mode>_nn
job type : نوع عملیات(export/import/sqlfile)
mode: تعیین حالت عملیات(full , table , schema ,…)
nn: شمارنده ای برای تعیین تعداد job هاست که از 01 شروع می شود.
برای مثال، نام دومین job import در حالت اسکیما بدین شکل می باشد:
‘sys_import_schema_02’ .
مثال :
~]$ expdp naser tables=cid.tbl_pub_dossier dumpfile=test_1.dmp directory=dump
. . .
FLASHBACK automatically enabled to preserve database integrity.
Starting “NASER”.”SYS_EXPORT_TABLE_03″: naser/******** tables=cid.tbl_pub_dossier dumpfile=test_1.dmp directory=dump
Estimate in progress using BLOCKS method…
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
Total estimation using BLOCKS method: 2.835 GB
. . .
نکته: برای بدست آوردن نام و وضعیت job در حال اجرا ، می توان از ویو های dba_datapump_jobs و یا dba_datapump_sessions استفاده نمود.
پروسس master یک جدول همنام با job ایحاد شده می سازد که به اصطلاح به آن جدول maser گفته می شود و در آن اطلاعاتی نظیر نام آبجکت ها ، نوع ، مالک، tablespace و اندازه ی آبجکت های در حال کار ، ترتیب آبجکتها برای استخراج و… ثبت شده است و پروسس master از این جدول برای شناسایی آبجکتهای مورد نظر و استخراج آنها استفاده می کند.
نام جدول master را می توان از ویوی dba_segments پیدا کرد:
SQL> select * from dba_segments s where s.segment_name=’JOB_NAME’;
نگاهی به اطلاعات جدول master :
SQL> select ex.object_type, ex.object_name, ex.object_schema, ex.object_tablespace,
ex.size_estimate, ex.object_row from naser.SYS_EXPORT_TABLE_02 ex
where ex.original_object_schema is not null;
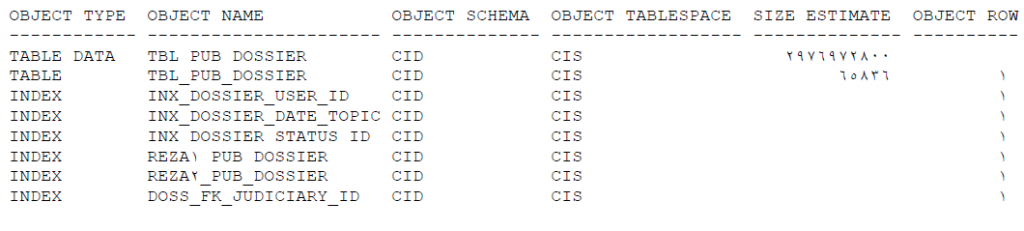
در صورتی که عملیات export/import موقتا متوقف شود، در اجرای مجدد job ، پروسس master با رجوع به این جدول ادامه کار را از سر می گیرد.
محتویات این جدول پس از اتمام عملیات استخراج ، در فایل دامپ نوشته شده و خود جدول حذف می شود. در هنگام بارگذاری داده ها در بانک مقصد ، ابتدا این اطلاعات توسط پروسس master از داخل فایل دامپ خوانده شده و براساس آن، آبجکتها بارگذاری می شوند.
همانطورکه گفته شد data pump یک فرایند سمت سرور (server side) است، به همین دلیل از یک آبجکت directory برای تعیین مسیر فایل دامپ و ذخیره آن برروی بانک مبدا استفاده می کند. قبل از اجرای دستور export/import ، می توان به شکل زیر یک directory در بانک ایجاد کرد:
SQL> create directory DIR_NAME as ‘/path/’;
مثال:
SQL> create directory mydump_dir as ‘/u01/oracle/dir_dump’;
Directory های ایجاد شده ، در ویوی all_directories قابل رویت هستند.
Data pump بصورت پیشفرض از یک دایرکتوری بنام data_pump_dir استفاده می کند که مسیر تنظیم شده برای آن “ $ORACLE_HOME/db_name/dpdump/ “ است و در ویوی all_directories هم قابل مشاهده است:
SQL> select * from all_directories;

نکته : توجه داشته باشید که مسیر و دایرکتوری که در دستور create directory تعیین می شود، باید قبلا ایجاد و دسترسی کاربر oracle به آن داده شده باشد.
با استفاده از دایرکتوری ایجاد شده می توان محل ایجاد و ذخیره فایل دامپ را مشخص نمود. مانند مثال زیر:
~]$ expdp naser directory=mydump_dir dumpfile=test.dmp tables=tbl_naser
ابزارهای EXPDP و IMPDP
تکنولوژی data pump برای انجام عملیات استخراج و بارگذاری اطلاعات از دو پکیج DBMS_DATAPUMP و DBMS_METADATA استفاده می کند.
با توجه به آنکه استفاده از این پکیج ها و پروسیجرهای آنها، با پیچیدگی ها و دشواریهای همراه است، همراه با data pump دو ابزار با نامهای (expdp (export data pump و (impdp (import data pump ارائه شده است که به ترتیب برای استخراج و بارگذاری داده ها، بصورت command line مورد استفاده قرار می گیرند.
البته این دو ابزار هم برای انجام استخراج و بارگذاری اطلاعات از پکیج های DBMS_DATAPUMP و DBMS_METADATA استفاده می کنند با این تفاوت که استفاده از آنها به مراتب آسانتر از بکارگیری مستقیم پکیج ها می باشد.
ساختار کلی استفاده از این ابزارها بدین ترتیب است :
expdp [username/passwd][parameter1=value1][parameter2=value2]…
impdp [username/passwd][parameter1=value1][parameter2=value2]…
دستور expdp را بدون هیچ پارامتری نیز می توان استفاده کرد که در این حالت پس از دریافت نام کاربر، از اسکیمای جاری، در مسیر ORACLE_HOME/db_name/dpdump$ دامپی با نام expdat.dmp تهیه می شود.
اما اگر دستور impdp را بدون پارامتری اجرا کنیم، پس از گرفتن نام کاربر، اگر در مسیر پیشفرض (ORACLE_HOME/db_name/dpdump$) فایلی بنام expdat.dmp وجود نداشته باشد، پیغام خطا صادر می شود.
دستورات expdp/impdp دارای پارامترهای متعددی هستند که به طور کلی به دو دسته قابل تقسیم اند:
پارامترهای اولیه: این پارامترها در زمان اجرای دستور تنظیم می شوند برای راحتی کار، می توان تمامی پارامترها را در یک فایل متنی قرار داد و با پارامتر parfile آنرا صدا زد.
پارامترها یا دستورات تعاملی : این پارامترها، که معمولا بصورت دستور استفاده می شوند، جهت مانیتور ، بررسی و کنترل عملیات ، در زمان اجرای export/import قابل استفاده هستند(در خط فرمان export> یا import> ).
برای رفتن به حالت تعاملی، می توان به دو صورت عمل کرد:
***در حین انجام عملیات، کلید Ctrl + c را فشار داده که دراین حالت ، نوشتن log برروی نمایشگر متوقف و خط فرمان export/import> نمایش داده می شود و سیستم آماده دریافت فرمان جدید است.
~]$ expdp naser tables=cid.tbl_dossier dumpfile=test3.dmp directory=dump
. . .
Processing object type TABLE_EXPORT/TABLE/TABLE_DATA
Processing object type TABLE_EXPORT/TABLE/PROCACT_INSTANCE
Processing object type TABLE_EXPORT/TABLE/TABLE
Processing object type TABLE_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type TABLE_EXPORT/TABLE/COMMENT
^C
Export>
***در خط فرمان سیستم عامل ، دستور expdp/impdp با پارامتر attach اجرا شود که مقدار پارامتر attach می تواند نام job باشد یا بدون مقدار استفاده شود که در این حالت آخرین job در حال اجرا را مشخص می کند.
~]$ expdp naser/naser attach=SYS_EXPORT_TABLE_03
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 – 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
Job: SYS_EXPORT_TABLE_03
Owner: NASER
. . .
Export>
=============================================================
~]$ impdp ali/123 attach=SYS_IMPORT_SCHEMA_02
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 – 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
Job: SYS_IMPORT_SCHEMA_02
Owner: ALI
. . .
Import>